오늘은 랜덤포레스트에 대해 알아보고자 한다.
랜덤포레스트는 기본적으로 앙상블 모델이기 때문에, 앙상블 기법과 간단한 개념도 복습하였다.
랜덤포레스트(Random Forest)


- 여러 결정트리로부터 분류 결과를 집계하여 결론을 내리는 기법
- 결정트리의 오버피팅을 막을 수 있는 전략
랜덤포레스트 프로세스
- 트리 생성에 무작위성 투입하여 결정트리를 많이 만듦
- 각 트리가 고유하게 만들어지도록 무작위 선택 (Bootstrap Sample)
- 기존 트리와 달리 무작위로 선택 후 후보들 중 최선의 테스트 도출
Bagging Features
- 결정트리를 만들 때 속성 선택에 있어 제한을 두어 다양성을 줌
- 일반적으로 특성(칼럼) 개수의 제곱근을 임의적으로 선택하는 특성 개수로 활용
- (ex. 25개의 칼럼이 있다면 5개의 칼럼 선택)
- 5개의 특성 중 정보 획득(information gain)이 가장 높은 것을 기준으로 데이터를 분할
랜덤포레스트 실습 (iris data 이용)
import pandas as pd
import numpy as np
import seaborn as sns
from sklearn.datasets import load_iris
iris = load_iris()
# X_data(특성값, 독립변수)와 y_data(결과값, 종속변수) 선언
X = iris.data
y = iris.target
# dataframe으로 살펴보기
df= pd.DataFrame(X, columns = iris.feature_names)
df.head()
# 훈련 / 테스트 데이터셋 나누기
from sklearn.model_selection import train_test_split
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.3) # 70% training and 30% test
# 랜덤포레스트 모델 피팅
from sklearn.ensemble import RandomForestClassifier
clf = RandomForestClassifier(n_estimators=100) # n_estimators : 생성할 결정트리의 개수
clf.fit(X_train, y_train)
# 테스트데이터셋 결과값 예측 및 정확도 출력
y_pred = clf.predict(X_test)
from sklearn import metrics
print("Accuracy:",metrics.accuracy_score(y_test, y_pred))>>>
Accuracy: 0.9555555555555556
# 특성 중요도
feature_imp = pd.Series(clf.feature_importances_, index=iris.feature_names).sort_values(ascending=False)
feature_imp>>>
petal width (cm) 0.459676
petal length (cm) 0.454799
sepal length (cm) 0.062654
sepal width (cm) 0.022870
dtype: float64# 특성 중요도 시각화
import matplotlib.pyplot as plt
%matplotlib inline
sns.barplot(x=feature_imp, y=feature_imp.index)
plt.xlabel('Feature Importance Score')
plt.ylabel('Features')
plt.title("Visualizing Important Features")
plt.show()
(참고)
앙상블 (Ensemble)
- 여러 머신러닝 모델을 연결하여 더 강력한 모델을 만드는 기법
앙상블 기법
부스팅 (Boosting)
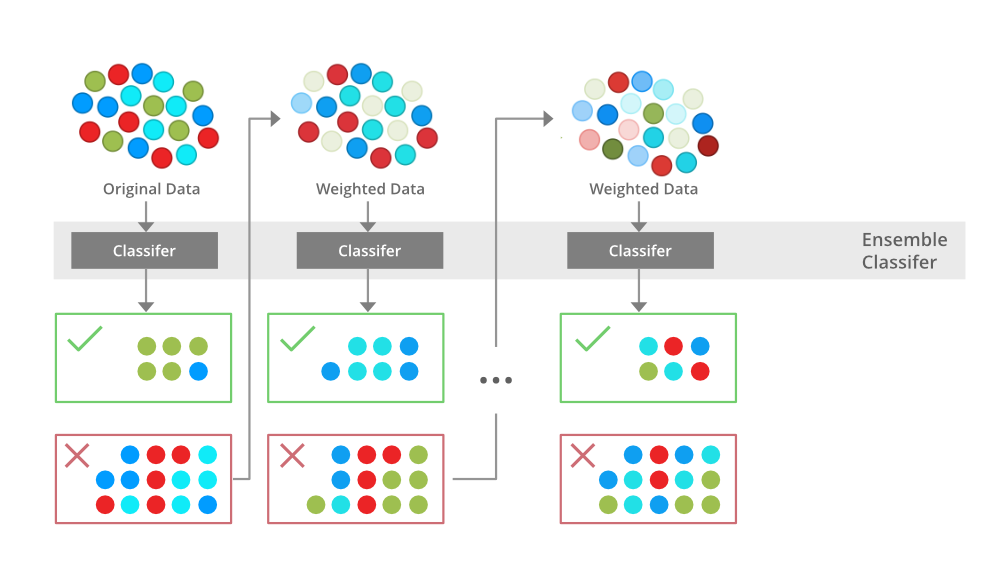
- 연속적으로 약한 모델을 결합시켜 학습시키는 방법
- 직전 모델이 잘못 분류한 에러를 반영해 다음 모델을 학습시키는 것을 반복
- ex) AdaBoost, XGBoost, GBM, LightGBM 등
스태킹 (Stacking)
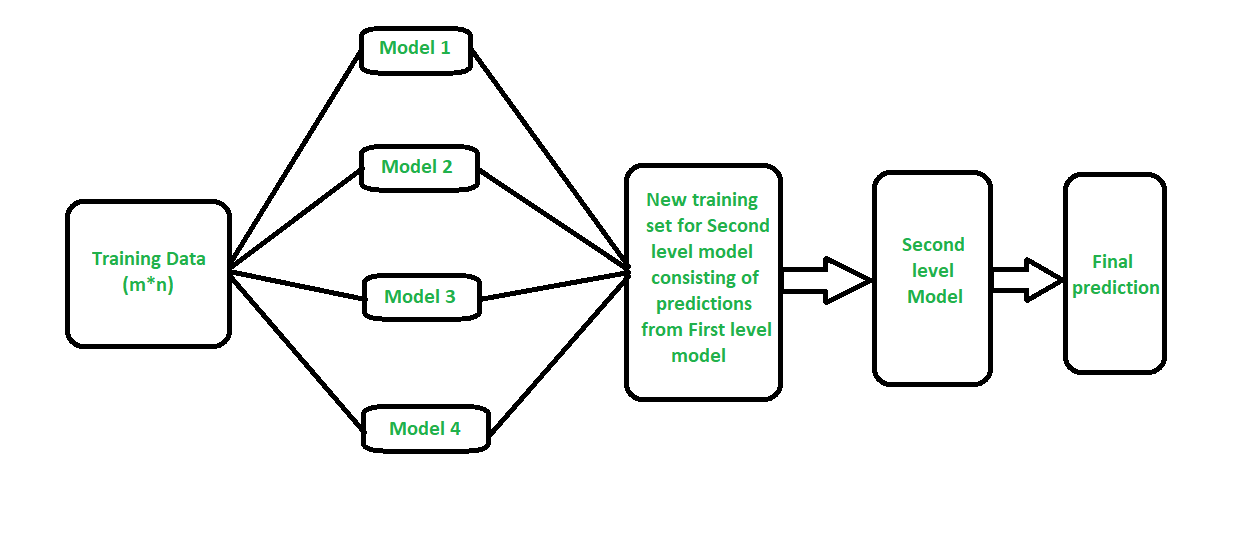
- 개별 모델이 예측한 데이터를 다시 meta data set으로 사용해서 학습
- Cross Validation을 통해 교차 검증
- 특정 형태의 샘플에서 어떤 종류의 단일 모델이 어떤 결과를 가지는지 학습가능
배깅 (Bagging)
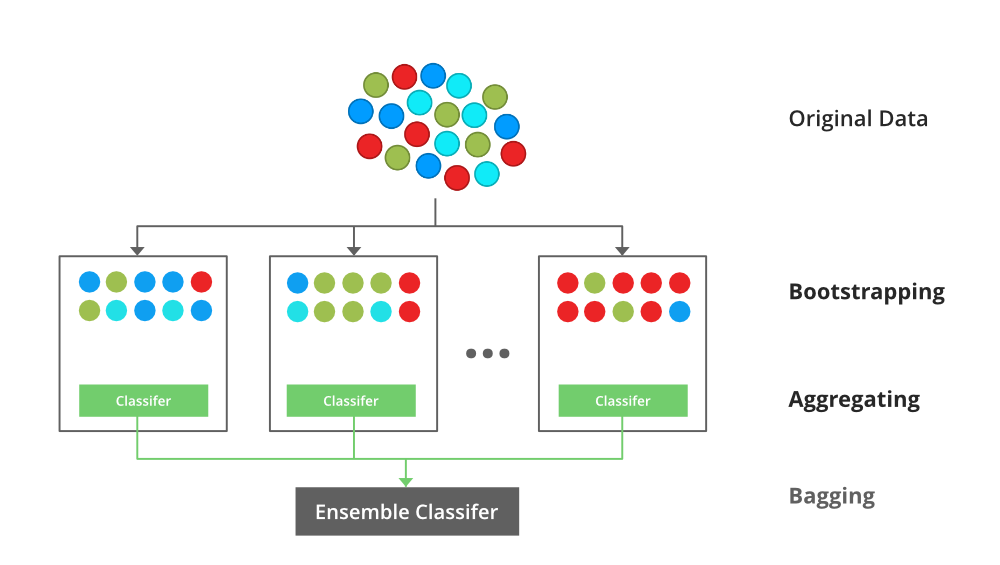
- 기존 훈련 데이터에서 샘플을 임의로 n개 뽑아 모델을 학습시키고, 그 결과를 집계하는 방법
- 부트스트랩 (bootstrap) : random sampling을 적용하는 방법을 일컫는 말, 무작위로 모집단을 구성하는 방법
- 중복 허용
- 각 결정트리는 모두 다른 데이터셋으로 학습하지만, 원래 훈련데이터의 부분집합으로 학습됨
- 범주형 데이터(categorical data)는 투표로 집계하고, 연속형 데이터(continuous data)는 평균으로 집계
- ex) 랜덤포레스트
References
https://eunsukimme.github.io/ml/2019/11/26/Random-Forest/
Random Forest(랜덤 포레스트) 개념 정리
Decision Tree는 overfitting될 가능성이 높다는 약점을 가지고 있습니다. 가지치기를 통해 트리의 최대 높이를 설정해 줄 수 있지만 이로써는 overfitting을 충분히 해결할 수 없습니다. 그러므로 좀더 일
eunsukimme.github.io
https://hleecaster.com/ml-random-forest-concept/
랜덤 포레스트(Random Forest) 쉽게 이해하기 - 아무튼 워라밸
본 포스팅에서는 의사결정 트리의 오버피팅 한계를 극복하기 위한 전략으로 랜덤 포레스트(Random Forest)라는 방법을 아주 쉽고 간단하게 설명하고자 한다. 파이썬 머신러닝 라이브러리 scikit-learn
hleecaster.com
https://data-matzip.tistory.com/4
1. 앙상블(Ensemble) 기법과 배깅(Bagging), 부스팅(Boosting), 스태킹(Stacking)
안녕하세요, 허브솔트에요. 저희 데이터맛집의 허브솔트 첫 글 주제로 앙상블이 당첨됐네요...! 요새 캐글의 상위권 메달을 휩쓸고 있는 대세 알고리즘이 앙상블 기법을 사용한 알고리즘의 한
data-matzip.tistory.com
https://www.geeksforgeeks.org/
GeeksforGeeks | A computer science portal for geeks
A Computer Science portal for geeks. It contains well written, well thought and well explained computer science and programming articles, quizzes and practice/competitive programming/company interview Questions.
www.geeksforgeeks.org
'Minding's Programming > Knowledge' 카테고리의 다른 글
| [ChatGPT] ChatGPT에게 여행일정을 짜달라고 해보았다. (0) | 2023.02.05 |
|---|---|
| [ML / DL] KNN (K-Nearest-Neighbor, K-최근접 이웃) (0) | 2022.01.25 |
| [ML / DL] 의사결정나무 (Decision Tree) (0) | 2022.01.20 |
| [ML/DL] 로지스틱 회귀 (Logistic Regression) (0) | 2022.01.19 |
| [ML/DL] 선형회귀 (Linear Regression) (0) | 2022.01.18 |