728x90
반응형
오늘은 KNN에 대해 공부해보았다.
KNN (K-Nearest-Neighbor, K-최근접 이웃)
- 새로운 데이터가 주어졌을 때 기존 데이터에서 가장 가까운 k개 이웃의 정보를 통해 새로운 데이터를 예측
- 분류문제라면 주변 이웃정보를 토대로 투표, 회귀문제라면 주변 이웃정보들의 평균이 예측값이 됨

KNN 프로세스
- 학습이 따로 필요하지 않은 방법론
- 새로운 데이터가 들어오면, 기존 데이터 사이의 거리를 재서 이웃들을 뽑음
- 모델을 별도로 구축하지 않는다는 뜻의 게으른 모델(Lazy model) / 거리 기반 학습(Instance-based Learning) 이라고 함
- 그 대신 학습모델보다 빠른 예측이 가능
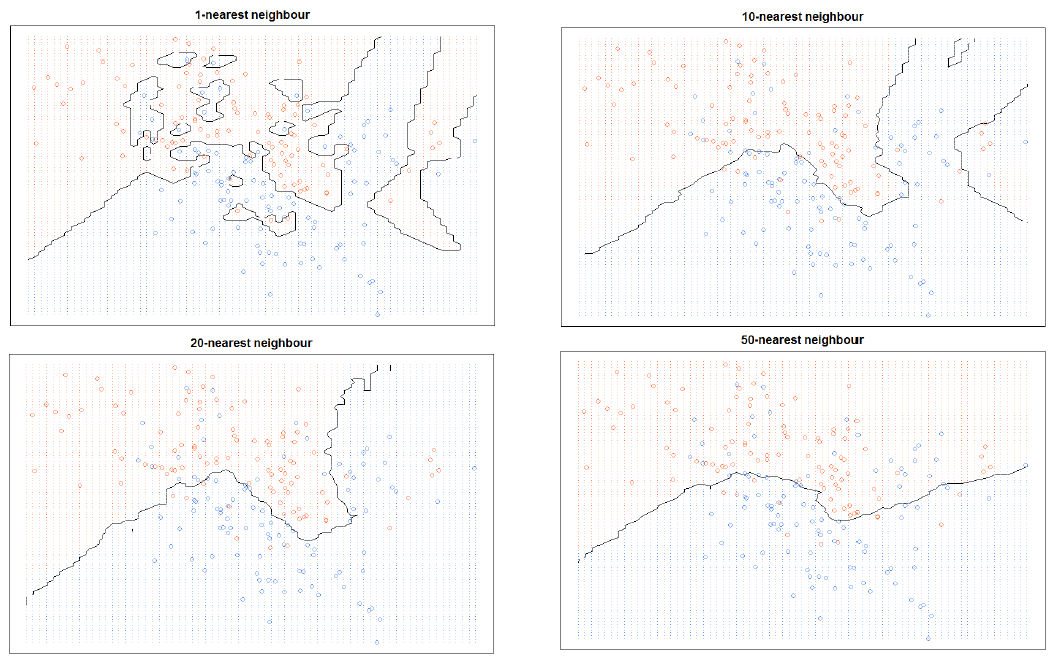
KNN 하이퍼파라미터
- 거리 측정 방법
- 탐색할 이웃 수(k)
- k가 작을경우 데이터의 지역적 특성을 지나치게 반영 (Overfitting)
- k가 클 경우 과하게 정규화 (Underfitting)
거리지표 (거리 측정 방법)
- KNN은 거리 측정 방법에 따라 결과가 달라지는 알고리즘임
유클라디안 거리 (Euclidean Distance)
- 가장 흔한 거리측정방법
- 두 데이터 사이 직선 최단거리를 의미
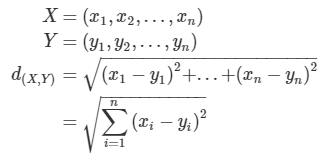

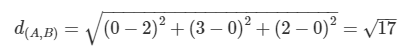
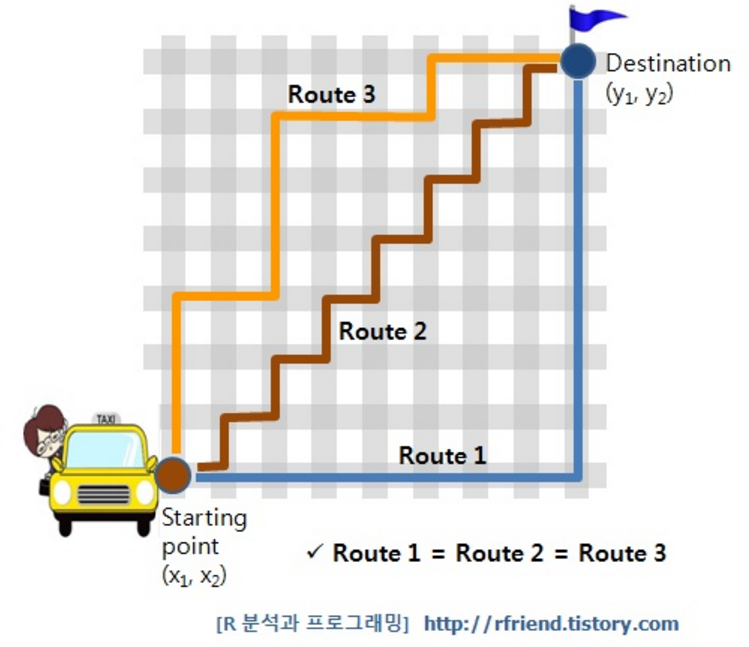
맨해튼 거리 (Manhattan Distance)
- A에서 B로 이동할 때 각 좌표축 방향(x 또는 y)으로만 이동할 경우에 계산되는 거리
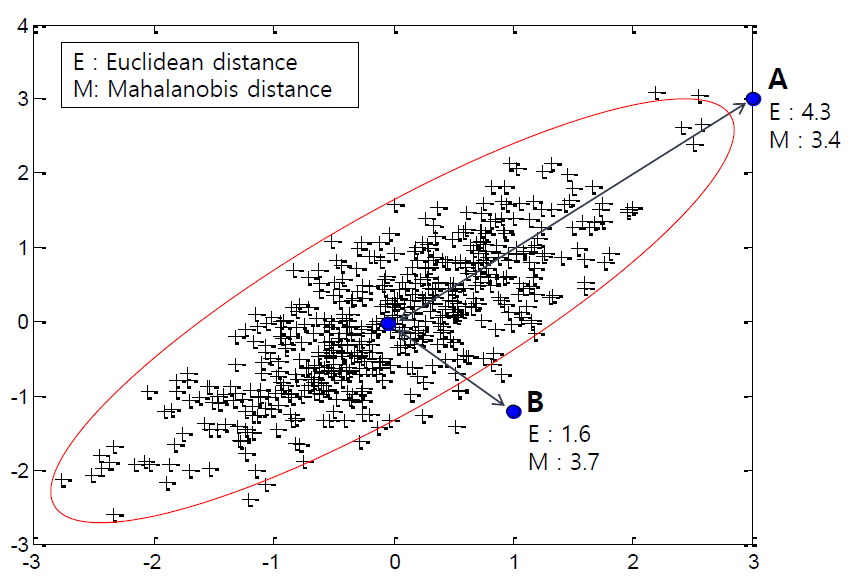
마할라노비스 거리 (Mahalanobis Distance)
- 변수 내 분산 / 변수 내 공분산을 모두 반영하여 거리를 계산하는 방식
- 평균과의 거리가 표준편차의 몇 배인지를 나타냄
- 변수 간 상관관계를 고려한 거리 지표

- 같은 거리일지라도 표준편차가 크다면(상관관계가 약하다면) 마할라노비스 거리는 멀게 계산 (B)
- 같은 거리일지라도 표준편차가 작다면(상관관계가 강하다면) 마할라노비스 거리는 가깝게 계산 (A)
- 아래 그림의 마할라노비스 거리는 A가 B보다 평균에 가까움
KNN 실습
import numpy as np
import pandas as pd
from sklearn.datasets import load_iris
import matplotlib.pyplot as plt
import seaborn as sns
iris = load_iris()
# X(독립변수)와 y(종속변수)로 선언
X = iris.data
y = iris.target
# 훈련 / 테스트 데이터셋 나누기
from sklearn.model_selection import train_test_split
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.3)
# KNN 모듈 임포트
from sklearn.neighbors import KNeighborsClassifier
knn = KNeighborsClassifier(n_neighbors = 5) # n_neighbors : 이웃의 개수
# 훈련 데이터셋에 모델 피팅
knn.fit(X_train, y_train)
# 예측 정확도 출력
from sklearn import metrics
print("Acc : ", knn.score(X_test, y_test))>>>
Acc : 0.9111111111111111
best K 찾기
# 가장 테스트 정확도가 높은 이웃의 개수(k) 찾기
k_range = range(1, 50) # 1~50의 범위 지정
scores = {}
scores_list = []
for k in k_range :
knn = KNeighborsClassifier(n_neighbors = k)
knn.fit(X_train, y_train) #모델피팅
y_pred = knn.predict(X_test) # 테스트데이터 예측
scores[k] = metrics.accuracy_score(y_test, y_pred) # 실제 정답과 예측값 비교하여 정확도 계산하고 scores 딕셔너리에 삽입
scores_list.append(metrics.accuracy_score(y_test, y_pred)) # 정확도 리스트에 추가
print("best K : ", scores_list.index(max(scores_list))+1)
print("prediction acc : " ,scores[scores_list.index(max(scores_list))+1])>>>
best K : 1
prediction acc : 0.9555555555555556
Reference
https://ratsgo.github.io/machine%20learning/2017/04/17/KNN/
K-Nearest Neighbor Algorithm · ratsgo's blog
이번 글에서는 K-최근접이웃(K-Nearest Neighbor, KNN) 알고리즘을 살펴보도록 하겠습니다. 이번 글은 고려대 강필성 교수님, 김성범 교수님 강의를 참고했습니다. 그럼 시작하겠습니다. 모델 개요 KNN
ratsgo.github.io
R, Python 분석과 프로그래밍의 친구 (by R Friend)
R, Python 분석과 프로그래밍, 통계, Machine Learning, Greenplum, PostgreSQL, Hive, 분석으로 세상보기, 독서일기
rfriend.tistory.com
728x90
'Minding's Programming > Knowledge' 카테고리의 다른 글
| 메타의 대규모 언어모델, LLAMA2 오픈소스 발표 (다운로드 방법) (1) | 2023.07.21 |
|---|---|
| [ChatGPT] ChatGPT에게 여행일정을 짜달라고 해보았다. (0) | 2023.02.05 |
| [ML/DL] 랜덤포레스트(Random Forest) & 앙상블(Ensemble) (0) | 2022.01.23 |
| [ML / DL] 의사결정나무 (Decision Tree) (0) | 2022.01.20 |
| [ML/DL] 로지스틱 회귀 (Logistic Regression) (0) | 2022.01.19 |