
마이닝의 개념
데이터의 발굴에서부터 해석으로 이어지는 일련의 과정을 뜻함.
- 분석 목적에 맞는 데이터를 추출(준비)
- 분석가능한 형태의 데이터로 변형
- 변형된 데이터를 이용해 상관관계 / 유사집단 / 변화 패턴 파악 등 분석 및 해석
간단한 데이터 직접 만들어보기
변수에 5개의 타율 데이터가 순서대로 나열되도록 코딩
# a : 변수이름
# <- : 해당 변수에 데이터를 입력
# c() : n개의 데이터로 구성된 벡터
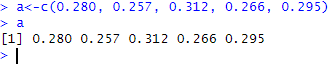
a<-c(0.280, 0.257, 0.312, 0.266, 0.295)
왼쪽 아래에 위치한 Console창에 위와 같이 입력해주면, a라는 변수에 5개의 타율데이터가 저장된다.

b<-c('Eric','John', 'Steven', 'Keith', 'Kim')위와 같이 문자형 데이터도 입력가능하다. 문자형 입력 시 따옴표가 필수로 표기되어야 한다.

Fangraphs 데이터를 R로 불러오기

컴퓨터에 저장된 파일을 R로 불러들이는 방법
1. 파일이 저장되어 있는 위치를 대략적으로 알 때
# read.csv() : csv파일을 R로 불러들이는 명령어
# file.choose() : 직접 검색해 파일을 찾음
# header=TRUE : 테이블의 첫 번째 행은 변수의 헤더(이름)
batting<-read.csv(file.choose(),header=TRUE)위 방법은 검색창을 띄워 csv파일을 찾는 방식이다.
2. 파일의 위치를 알고있을 때
batting<-read.csv('파일 경로')
3. Import Dataset을 이용





좌측 상단과 우측상단에 위와 같이 데이터셋이 표시되면 Import 성공이다.
빅데이터에서 필요한 데이터 분리하기
규모가 큰 데이터를 분석목적에 맞게 정리하는 법을 배우기 위해 메이저리그의 많은 기록을 담고 있는 Lahman 데이터를 이용한다.
# Lahman 데이터 패키지 설치
install.packages('패키지 이름')
install.packages('Lahman')

설치된 패키지를 라이브러리로 옮기기 (사용 대기시키기)
library(Lahman)한 번 설치된 패키지는 삭제하지 않는 이상 R에 계속 남아있으나, 사용하기 위해서는 라이브러리에 옮겨줘야 한다.
라만 데이터베이스 직접 살펴보기
# Lahman 데이터베이스는 28개의 하위 테이블 존재
# 테이블을 직접 확인하고 싶을때 두 가지 명령어 사용
data('테이블 이름')
view(테이블 이름)# Batting 테이블을 보고 싶을 때
data('Batting')
View(Batting)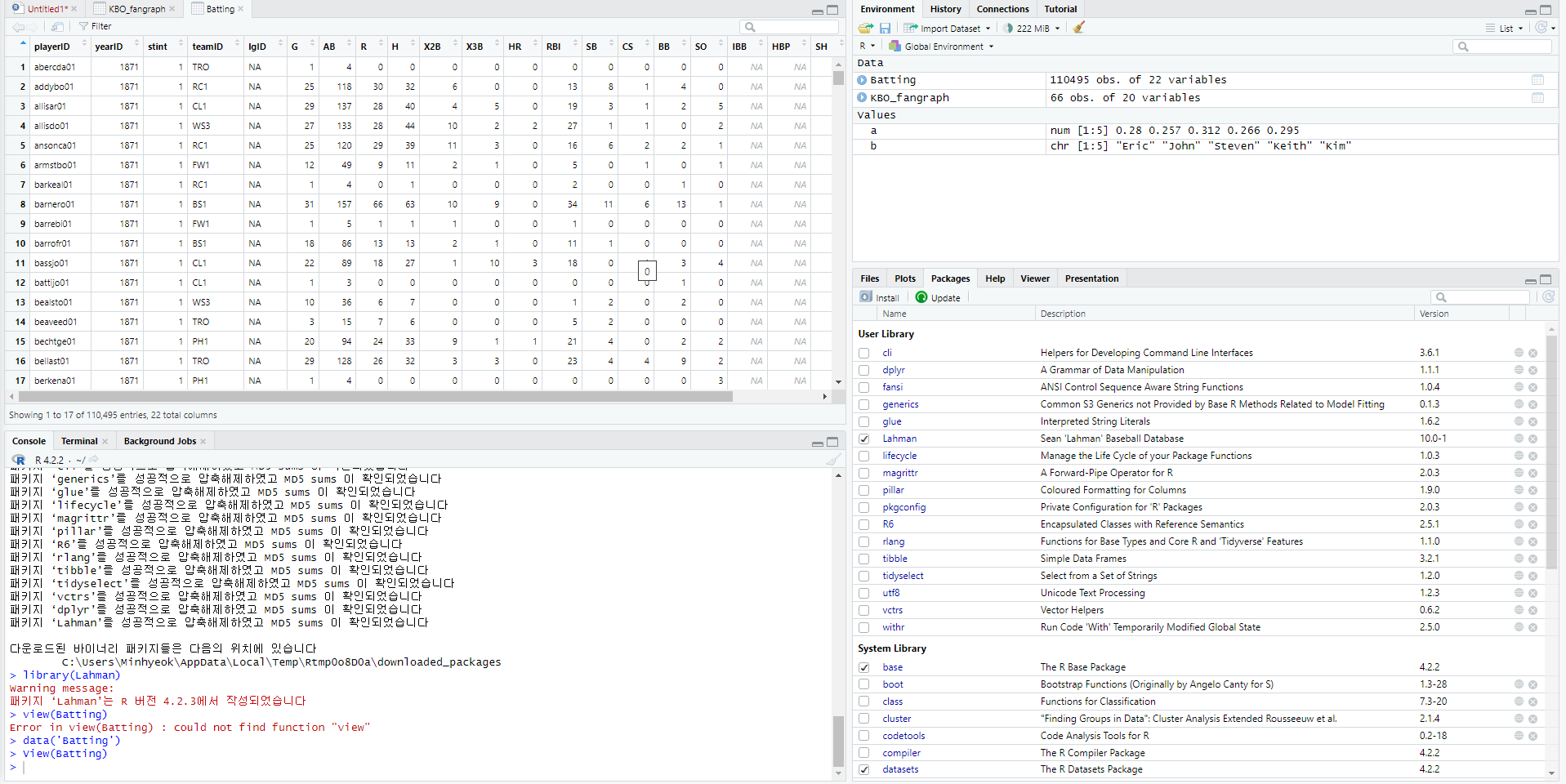

Lahman 데이터에서 자주 쓰이는 테이블
Master : 선수들의 신상 정보
Batting : 타격
Pitching : 투구
Fielding : 수비
Master에서 선수 이름을 통해 선수의 ID를 찾고, Batting/Pitching/Fielding에서 해당 선수의 기록을 찾을 수 있다.
그리고 그 데이터를 특정 변수에 저장시키는 방법은 아래와 같다.
# 자신이 찾는 MLB 특정 선수의 데이터를 b에 저장하는 방법
b<-subset(Pitching, playerID=='투수 ID')
b<-subset(Batting, PlayerID=='타자 ID')
# 대괄호 이용
b<-Batting[Batting$playerID=='타자 ID',]대괄호 이용의 경우
Batting[행, 열] 에 해당하는 데이터를 가져오라는 뜻이다.
위 코드에서는, Batting테이블의 타자 ID에 해당하는 행 전부 / 열 전부를 가져오라는 뜻이된다. (비어있으면 조건없이 전부)
작업했던 코딩과 데이터 정보 저장하기 / 다시 사용하기
사용했던 코드를 재활용할 수 있도록, 작업정보를 R Script로 저장하는 방법이다.
작업한 코드를 Script에 다음과 같이 작성하고, 디스캣 모양을 눌러 저장한다.



위처럼 스크립트를 이용해 작업시간을 최소화할 수 있다. (반복 작업 최소화)
순서가 같은 테이블 합치기 : cbind(), rbind()
1. cbind()
Pandas에서 Dataframe을 합치는 과정과 비슷하다. 실습하기 위해 두 개의 테이블을 만들어본다.
a<-c('A', 'B', 'C', 'D', 'E')
b<-c(0.280, 0.257, 0.312, 0.197, 0.288)두 변수를 하나의 테이블로 통합하기 위해서는 cbind()라는 명령어로 새로운 이름의 테이블을 만든다.
명령어에 들어가는 변수의 순서대로 결과 테이블이 만들어진다.
c<-cbind(a,b)
c # c출력
>>>
a b
[1,] "A" "0.28"
[2,] "B" "0.257"
[3,] "C" "0.312"
[4,] "D" "0.197"
[5,] "E" "0.288"선수이름과 타율 순서대로 테이블이 완성됐다. 대괄호 안에 있는 숫자 [1,] 등은 데이터의 행을 나타낸다.
열의 이름은 a,b 등 알파벳 순서대로 정해지는데, 아래 코드를 통해 열 이름을 변경할 수 있다.
colnames(c)<- c('player', 'avg')
c
>>>
player avg
[1,] "A" "0.28"
[2,] "B" "0.257"
[3,] "C" "0.312"
[4,] "D" "0.197"
[5,] "E" "0.288"cbind()를 사용할 때 주의할 점
- 기존 변수와 추가할 데이터 간 순서가 동일한지 확인해야 함.
- Python DataFrame에서 열 추가를 하는 방식과 똑같이 순서대로 데이터가 입력되기 때문
2. rbind()
rbind()는 Python DataFrame에서 행 추가를 하는 방식과 같다. 말 그대로 행 추가다.
a, b를 합친 c에 다음과 같이 생긴 데이터를 합칠 때 사용한다.
d<-c('F', '0.322')
d
>>>
[1] "F" "0.322"e<-rbind(c,d)
e
>>>
player avg
"A" "0.28"
"B" "0.257"
"C" "0.312"
"D" "0.197"
"E" "0.288"
"F" "0.322"기존 데이터 아래에 추가된 모습이 보인다.
순서가 다른 테이블 합치기: merge()
각 선수들의 순서가 맞지 않게 나열된 테이블끼리 합치기 위해서는 merge()를 통해 공통 변수를 찾아 연결해줘야 한다.
# matrix() 명령어를 통해 테이블을 한 번에 만들어주기
d<- matrix(c('C', 'F', 'A', 'D', 'B', 'E', 26, 22, 31, 30, 38, 29),ncol=2)
d
>>>
[,1] [,2]
[1,] "C" "26"
[2,] "F" "22"
[3,] "A" "31"
[4,] "D" "30"
[5,] "B" "38"
[6,] "E" "29"
# 칼럼 이름 변경
colnames(d) <- c('player', 'age')앞 실습을 통해 만들어 두었던 e테이블(선수, 타율)과 merge()를 통해 합쳐본다.
f<-merge(e,d, by='player')
f
>>>
player avg age
1 A 0.28 31
2 B 0.257 38
3 C 0.312 26
4 D 0.197 30
5 E 0.288 29
6 F 0.322 22
양적 변수를 명목 변수로 바꾸기
특정 변수를 이항/다항 변수로 바꿔 특정 집단 간 비교를 하기 위해서는 전처리 과정이 필요하다.
위에서 만들어진 f의 age열을 이항 변수로 바꿔보는 작업으로 그 과정을 알아본다.
우선 age변수가 수치(numeric)변수인지 확인해야 한다. 확인은 str(테이블이름)을 사용한다.
str(f)
>>>
'data.frame': 6 obs. of 3 variables:
$ player: chr "A" "B" "C" "D" ...
$ avg : chr "0.28" "0.257" "0.312" "0.197" ...
$ age : chr "31" "38" "26" "30" ...책 본문에서는 factor라는 요인 변수로 인식되는데, 내 환경에서는 모두 문자형으로 인식된다(?)
아무튼, 이항 변수로 바꿔주기 위해 수치 변수로 변환해준다. as.numeric()을 이용한다.
f$age<-as.numeric(f$age) # f의 age만 numeric형으로 변환
f
>>> # 겉보기에는 달라지지 않는다.
player avg age
1 A 0.28 31
2 B 0.257 38
3 C 0.312 26
4 D 0.197 30
5 E 0.288 29
6 F 0.322 22
str(f)
>>>
'data.frame': 6 obs. of 3 variables:
$ player: chr "A" "B" "C" "D" ...
$ avg : chr "0.28" "0.257" "0.312" "0.197" ...
$ age : num 31 38 26 30 29 22 # 변환완료이 다음 ifelse()를 이용해 특정 조건을 기준으로 나눠준다. 필자는 29세를 기준으로 그룹을 나눴다.
# 29세를 넘으면 1, 아니면 0
g <- ifelse(f$age>29,1,0)
g
>>>
[1] 1 1 0 1 0 0기준으로 나눈 그룹을 cbind()를 통해 h라는 새로운 변수에 합쳐 저장해준다.
h<-cbind(f,g)
h
>>>
player avg age g
1 A 0.28 31 1
2 B 0.257 38 1
3 C 0.312 26 0
4 D 0.197 30 1
5 E 0.288 29 0
6 F 0.322 22 0
R에서 괄호 사용법
1. 소괄호 ()
- 명령어의 필수요소나 추가 요소 입력
ex)
c<-merge(a,b,by='Team')
2. 중괄호 {}
- 분석자의 필요에 따라 자신의 만든 공식을 반복적으로 적용해야 할 경우
- {}안에는 특정 공식이 들어감
- Python의 함수(def)와 비슷
ex)
a<-function(H,AB){H/AB}
a(10,35)
>>>
0.2857143
3. 대괄호 []
- 전체 DB에서 특정 부분에 있는 변수 or 관측값을 지정
- 행렬의 예시를 생각하면 됨 ([1,3]의 경우 첫 번째 행 / 세 번째 열에 있는 데이터 의미)
- 행 또는 열의 이름으로도 사용가능
ex)
b<-a[a$Team=='Giants',]
결측값 제거하기
a라는 테이블에서 결측값을 제거한 뒤 b에 저장하는 코드
b<-na.omit(a)
조건문 사용하기
#OR
a <- subset(Batting, PlayerID=='altuvjo01'|playerID=='zobribe01')
#AND
b <- subset(a,yearID>2011&yearID<2017)
#XOR
c <- subset(b, !(yearID==2014|yearID==2015))
계속 사용할 테이블 고정하기
특별한 명령이 있을 때까지 해당 테이블만 사용하고 싶다면, 이 방법을 이용해 분석 작업을 편하게 할 수 있다.
예를 들어 Batting$AVG 처럼 Batting$을 계속 적어야하는게 불편하다면, 아래 방법을 이용해 이를 생략할 수 있다.
attach(테이블 이름)
attach(Batting)
'Minding's Reading > 메이저리그 야구 통계학 2e' 카테고리의 다른 글
| [메이저리그 야구 통계학 2/e] 4장 - 상관관계는 인과관계가 아니다(1) (0) | 2023.05.01 |
|---|---|
| [메이저리그 야구 통계학 2/e] 3장 - 선수의 능력은 어떻게 측정할 것인가?(2) (0) | 2023.04.25 |
| [메이저리그 야구 통계학 2/e] 3장 - 선수의 능력은 어떻게 측정할 것인가?(1) (0) | 2023.04.24 |
| [메이저리그 야구 통계학 2/e] R 설치, R Studio(Posit) 설치 (0) | 2023.02.06 |
| [메이저리그 야구 통계학 2/e] 책 읽기 전 변수 개념 정리 (0) | 2023.02.01 |