Spark의 DB와 테이블
SparkSQL을 통해 임시 테이블을 만들어 SQL 조작이 가능하지만, Spark는 기본적으로 인메모리 기반이기 때문에, 세션이 종료되면 카탈로그라고 불리는 테이블과 뷰가 사라진다. 이 문제로 인해 Spark에서는 계속해서 사용해야 하는 테이블을 그때 그때 불러와줘야 하는 문제가 발생한다.
Hive 메타스토어
이를 해결하기 위해 Disk에 저장이 가능한 Hive와 호환이 되는 Persistent라는 카탈로그를 제공한다. 각 테이블들은 DB라고 부르는 폴더와 같은 구조로 관리된다.
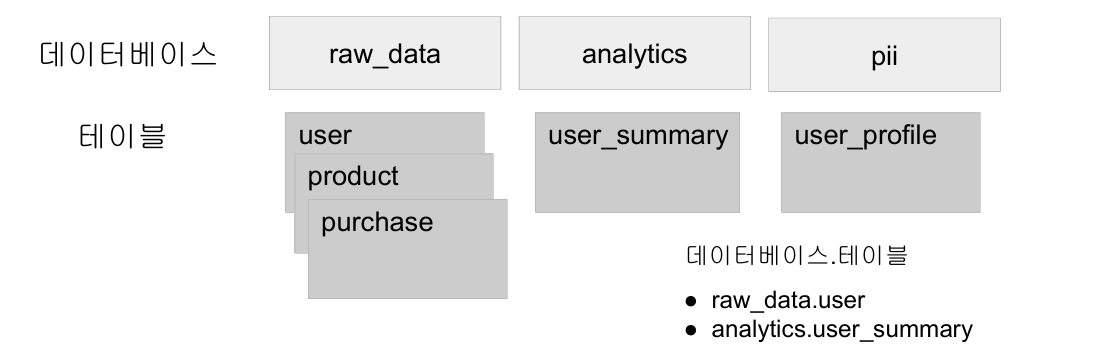
위와 같이 스토리지 기반의 테이블은 기본적으로 HDFS오 Parquet 포맷을 사용하며, Hive와 호환되는 메타스토어를 사용한다. 여기엔 두 종류의 테이블이 존재한다.
- Managed Table: Spark에서 실제 데이터와 메타 데이터 모두 관리
- Unmanaged (External) Table: Spark에서 메타 데이터만 관리
스토리지 기반 카탈로그 사용 방법
Hive와 호환되는 메타스토어를 사용하기 위해서는, SparkSession을 생성할 때 enableHiveSupport()라는 함수를 호출할 수 있다. 기본으로 'default'라는 이름의 데이터베이스(폴더)가 생성된다.
from pyspark.sql import SparkSession
spark = SparkSession \
.builder \
.appName("Python Spark Hive") \
.enableHiveSupport() \
.getOrCreate()
Managed Table 사용방법
2가지 방법을 통해 테이블을 생성하고, 이 테이블이 저장될 위치를 가리키면 해당 위치에 저장된다. 기본 데이터 포맷은 parquet이다. 태블로나 PowerBi 등 외부에서도 Spark 테이블을 통해 처리하면 JDBC/ODBC등으로 Spark에 연결해 처리할 수 있다는 장점도 있다. 일반적으로 External Table보다 Managed Table로 처리하는 것이 성능이 우수하다.
# 테이블 생성(.saveAsTable() 또는 SQL의 CREATE 사용)
dataframe.saveAsTable("TableName")
# spark.sql.warehouse.dir("저장할위치")
External Table 사용방법
이미 HDFS에 존재하는 데이터에 스키마를 정의해서 사용하는 방법이다. LOCATION이라는 프로퍼티를 사용하고, 이 경우 실제 데이터는 제외한 메타데이터만 Spark 카탈로그에 기록된다.
CREATE TABLE table_name (
column1 type1,
column2 type2,
column3 type3,
…
)
USING PARQUET
LOCATION 'hdfs_path';
'Minding's Programming > Spark' 카테고리의 다른 글
| [Spark/pySpark] SparkSQL UDF(User Define Function) (0) | 2024.12.02 |
|---|---|
| [Spark] Spark의 개념, 구조, 프로그램 실행 옵션 (2) | 2024.11.28 |
| [Hadoop] MapReduce 프로그래밍이란? (0) | 2024.11.28 |
| [Hadoop] 하둡의 분산처리 시스템, YARN 개념 정리 (0) | 2024.11.28 |