Spark?
Spark는 2013년에 출시된 Scala 기반의 빅데이터 처리 기술로, YARN 등을 분산환경으로 사용한다. 최근엔 MapReduce와 Hive 대신 Spark가 많이 선택받고 있다.
Spark의 구성 (3.0 기준)
Spark 3.0 기준 아래와 같은 라이브러리로 구성되어 있다.
- Spark Core: 각 App을 실행시키는 엔진 역할
- Spark SQL: SQL 등으로 DB, Dataframe 등을 조작할 수 있는 기능
- Spark ML: 머신러닝 기능을 사용할 수 있음
- Spark Streaming
- Spark GraphX
Spark의 특징 (vs MapReduce)
- Spark는 메모리를 우선 사용하며, 메모리가 부족해지면 디스크를 사용한다.
- MapReduce의 경우 디스크를 사용해 Spark에 비해 속도가 느림
- Spark는 하둡(YARN) 이외에도 다른 분산 컴퓨팅 환경을 지원한다.
- k8s, Mesos 등 환경 지원
- Spark는 Pandas DataFrame과 개념적으로 동일한 데이터 구조도 지원함.
- MapReduce의 경우 key-value 포맷만 지원
- 배치 데이터 처리, 스트림 데이터 처리, SQL, 머신러닝 등 다양한 컴퓨팅 방식 지원
Spark 프로그래밍 API
Spark는 2가지 방식의 API를 지원한다.
- RDD (Resilient Distrubuted Dataset)
- low-level의 API로, 세밀한 제어가 가능하지만 코딩 복잡도가 올라감
- DataFrame & Dataset
- high-levle의 API로, 최근에 점점 많이 사용되는 추세
- Pandas의 Dataframe과 흡사한 형태로 데이터 조작 가능
- 하지만, 꼭 필요한 경우가 아니라면 사용할 필요 없음 (ex. 머신러닝, feature engineering 등)
Spark 데이터 시스템 사용 예시
대표적으로 Spark가 사용되는 예시는 아래와 같다.
- 대용량 비구조화된 데이터 처리 (ETL, ELT)
- ML 모델에 사용되는 대용량 피쳐 처리 (배치/스트림)
- Spark ML을 이용한 대용량 훈련 데이터 모델 학습
Spark 프로그램의 구조
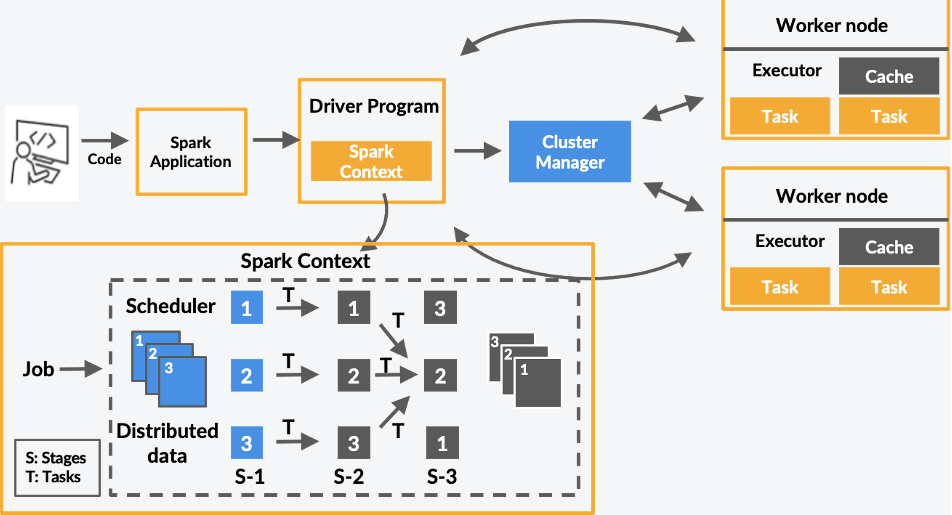
Spark는 크게 Driver와 Executer로 구분 지을 수 있다. Driver는 실행 코드의 마스터 역할, Executer는 실제 task를 실행하는 역할을 수행한다.
좀 더 자세히 들어가서 각각의 역할에 대해 알아보자면,
Driver
Driver는 실행 모드에 따라 실행 되는 곳이 달라진다.
- Client: 노트북, spark shell 등처럼 개발/학습용으로 사용할 때
- Cluster: 개발 후 Spark Cluster 안에서 실행할 때 (실제 서비스용)
또한 보통 SparkContext를 만들어 Spark 클러스터와 통신을 수행한다. 통신 상대는 아래와 같다.
- Cluster Manager (=YARN의 경우 Resource Manager)
- Executer
Executer
실제 task를 실행해주는 역할이며, YARN에서는 Container가 된다.
Spark 데이터 시스템 아키텍처

Spark는 기본적으로 Resource Manager라고 불리는 YARN, K8s 등 위에서 작동한다. 내부 데이터는 HDFS, AWS S3등에서 받아오는 형태이다. 외부에 있는 데이터(ex. RDS 등)는 주기적인 ETL을 통해서 최신화해 내부 데이터로 가져오거나, 필요할 때마다 바로 처리하는 방법을 사용한다. 이 처리 과정을 통해 외부 DB로 적재시키기도 한다.
Spark의 병렬 데이터 처리
Hadoop Map의 데이터 블록처럼, Spark에서는 파티션(partition)이라고 불리는 데이터 처리 단위가 존재한다. 하둡과 마찬가지로 128MB의 기본크기를 가지고 있다. 이렇게 파티션 단위로 나눠진 데이터를 메모리에 로드하여 Executor를 배정하고, 각각 따로 동시에 처리한다.

위처럼 데이터(최상단)를 파티션으로 나눈 뒤, 이를 각 Executor에 배정해 데이터를 처리한다.
셔플링 (Shuffling)
파티션 간 데이터 이동이 필요한 경우에는 셔플링이라는 현상이 발생한다. 대표적으로 아래 경우와 같다.
- 명시적 파티션을 새롭게 하는 경우(ex. 파티션 수를 줄이기)
- 시스템에 의해 이뤄지는 셔플링(ex. Group By, Sort 등)
셔플링이 발생할 때는 Network를 타고 데이터가 이동한다.(서버가 여러 대인 경우) 오퍼레이션에 따라 파티션 수가 결정되며(기본값은 200개가 최대), random, hashing partition, range partition등의 오퍼레이션 옵션이 있다. 셔플링이 일어날 때는 Data Skew가 발생할 수 있다는 점을 유의하자.
'Minding's Programming > Spark' 카테고리의 다른 글
| [Spark/Hive] Spark에서 Hive 메타 스토어 사용하기 (0) | 2024.12.02 |
|---|---|
| [Spark/pySpark] SparkSQL UDF(User Define Function) (0) | 2024.12.02 |
| [Hadoop] MapReduce 프로그래밍이란? (0) | 2024.11.28 |
| [Hadoop] 하둡의 분산처리 시스템, YARN 개념 정리 (0) | 2024.11.28 |


