728x90
반응형
MapReduce 프로그래밍의 특징
MapReduce 프로그래밍은 기본적으로 빅 데이터 처리를 위해 만들어졌기 때문에, 일반 데이터 처리와는 다른 특징이 있다. 큰 특징은 아래와 같다.
- 데이터 셋은 Key, Value의 집합이며 변경 불가(immutable) - 포맷은 하나로 고정
- 데이터 조작은 map과 reduce 2개의 오퍼레이션으로만 가능
- 이 2개의 오퍼레이션은 항상 하나의 쌍으로 연속 실행
- 이 두 오퍼레이션 코드를 개발자가 채워야 함
- MapReduce 시스템이 Map의 결과를 Reduce단으로 모아줌
- 위 단계를 셔플링이라고 부르며, Network단을 통한 데이터 이동이 발생
- Map의 결과 중 key가 같은 것을 모아주고 Reduce로 보냄
Map과 Reduce
Map: (k, v) --> [(k', v')*]
- 입력은 시스템에 의해 주어지며, 입력으로 지정된 HDFS 파일에서 넘어옴
- key, value 페어를 새로운 key, value 페어 리스트로 변환한다.
- 출력: 입력과 동일한 key, value 페어를 출력하거나, 출력이 없어도 됨
Reduce: (k', [v1', v2', v3', v4' ...]) --> (k", v")
- 입력은 시스템에 의해 주어지는데, Map의 출력 중 같은 key를 갖는 key, value 페어를 시스템이 묶어 입력
- key, value 리스트를 새로운 key, value 페어로 변환
- SQL의 GROUP BY와 흡사한 모습
- 출력이 HDFS에 저장됨
예시: WordCount
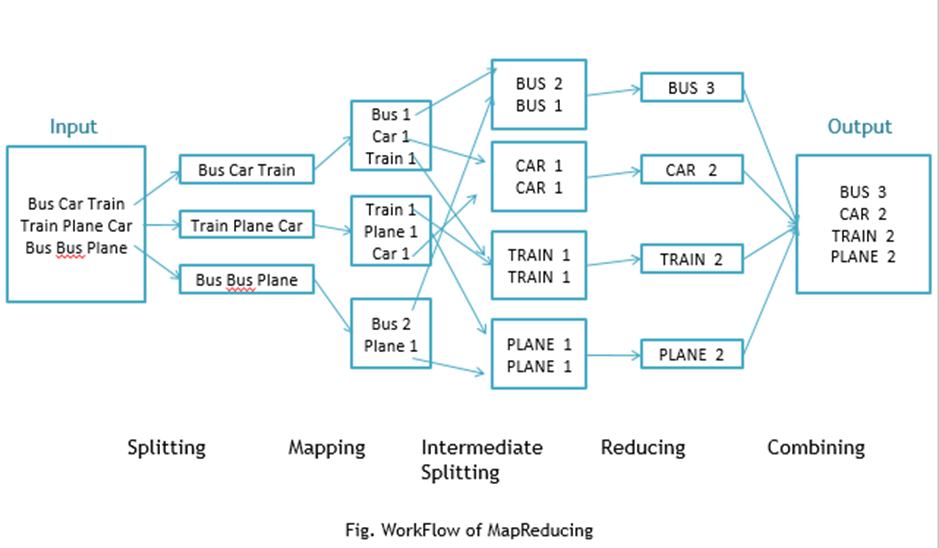
MapReduce로 단어를 세는 프로그램을 작동시켜본다고 가정하면, 위와 같은 흐름으로 나타난다.
- 3개의 문장이 input으로 주어진다.
- 각 문장 별로 단어를 나누어, mapping을 통해 단어 수를 센다
- 같은 key를 가진 단어를 그룹으로 묶는다.
- 같은 key를 가진 단어의 그룹을 Reducing하여, Input의 모든 문장에서 해당 단어가 나온 횟수를 표시한다.
- 결과값을 출력한다.
728x90
'Minding's Programming > Spark' 카테고리의 다른 글
| [Spark/Hive] Spark에서 Hive 메타 스토어 사용하기 (0) | 2024.12.02 |
|---|---|
| [Spark/pySpark] SparkSQL UDF(User Define Function) (0) | 2024.12.02 |
| [Spark] Spark의 개념, 구조, 프로그램 실행 옵션 (2) | 2024.11.28 |
| [Hadoop] 하둡의 분산처리 시스템, YARN 개념 정리 (0) | 2024.11.28 |