https://ieeexplore.ieee.org/document/8575424
본 논문에서는 Object Tracker인 SORT와 DeepSORT를 이용하여 객체의 속도를 추정하는 알고리즘을 소개한다.
Abstract
본 연구에서는 단안 비디오에서 차량 속도 추정을 위한 새로운 접근 방식을 제시한다. 파이프라인은 다중 객체 감지, 강력한 추적 및 속도 추정을 위한 모듈로 구성된다. 추적 알고리즘은 개별 차량을 공동으로 추적하고 이미지 영역의 속도를 추정하는 기능을 가지고 있다. 그러나 카메라 매개 변수를 사용할 수 없는 경우가 많고 장면에 광범위한 변화가 존재하기 때문에 영상 영역의 측정을 실제 세계로 변환하는 것은 어려운 일이다. 우리는 변환을 근사화하기 위한 간단한 2단계 알고리듬을 제안한다. 먼저 아핀 속성을 복원하기 위해 이미지를 수정한 다음 각 장면에 대해 스케일링 계수가 보정됩니다. NVIDIA AI City 과제에서 트래픽 속도 분석 데이터 세트에 대한 광범위한 실험을 통해 제안된 방법의 효과를 보여준다. 우리는 제한되지 않은 교통 비디오에서 차량 속도 추정 작업에 대해 차량 감지 및 추적에서 1.0의 탐지율과 9.54(mph)의 루트 평균 제곱 오차를 달성한다.
Introduction
- 딥러닝과 자율주행 기술의 인기가 많아지면서, 차량 속도 측정, 도로의 비정상적 사건 탐지(교통사고 등), 차량 재식별 등 지능형 교통 분석 분야가 활발한 연구가 이뤄지고 있음
- 이 연구에서는 traffic congestions(교통혼잡)이나 anomalous events(비정상적 사건)을 탐지할 수 있는 교통 분석의 crucial information(중요한 정보)인 차량의 속도를 측정하는 것에 대해 다룸
- Specifically(특히), 이 연구에서는 monocular videos(단안 카메라)에서의 차량 속도 측정 문제를 고려한다.
- 문제를 해결하는 일에는 크게 두 가지 측면의 과제가 있음
1. 강력한 차량 탐지 및 추적 알고리즘은 시간이 변화함에 따라 달라지는 차의 방향(orientation)과 조명 조건 내에서 개별 차량의 위치를 알아내는 것(localize)을 필요로 함
2. 이미지 공간에서 실제 세계로의 변환은 종종 사용할 수 없으며 LIDAR과 같은 값비싼 측정 장비가 필요함
- To address these issues(이러한 문제를 해결하기 위해), 우리는 단안 비디오에 대해 works reliably(안정적으로 작동)하며 최소한의 측정만 필요한 차량 속도 추정을 위한 반자동 접근 방식을 제시.
- 딥러닝은 여러 컴퓨터 비전 연구에서 State-of-the-art(최첨단) 결과를 달성했지만, traffic surveillance (교통 감시) 영역에서의 비전 연구의 응용은 연구되지 않고 있음
- 기존의 많은 지능형 교통 시스템(ITS)은 여전히 소음에 민감한 수작업 기능을 사용하여 background subtraction(배경 감산) 및 차량 분할과 같은 옛 기술을 기반으로 작동
- 본 연구에서는 안정적으로 bounding box를 만들 기 위해 Detector로 Mask-RCNN 사용하고, 그 bbox를 효과적으로 추적하는 SORT와 DeepSORT 알고리즘으로 개별 차량 추적 및 속도 추정하는 데 사용
- Arguably(의심할 여지 없이), 차량 속도 추정에서 가장 어려운 작업은 이미지 영역에서 실제 영역으로 변환을 모델링하여 차량의 속도를 이미지 영역에서 취한 측정에서 추론할 수 있도록 하는 것.
- 이전 방법의 대부분은 extensive measurements(광범위한 측정)과 camera calibration(카메라 보정)을 통해 3D 세계의 포인트와 image plane(이미지 평면) 사이의 accurate correspondences (정확한 대응성)을 얻는 데 resort(의존)하지만, 우리는 변환을 approximate (근사화)하기 위한 간단한 2단계 알고리즘을 제안
1. affine properties(아핀 속성)을 to restore(복원하기 위해) 이미지의 vanishing points(소멸 지점)을 사용하여 rectifying transformation(수정 변환)을 estimate(추정)
--> 영상에서 측정된 속도를 현실과 correspondingly(상응하게) 수정 가능
2. 그런 다음 실제 차선 폭을 수정된 이미지의 차선 폭과 비교하여 이미지 영역에서 실제 세계로의 스케일링 계수를 측정
--> 선형 보간법 사용해 scene의 평면 이외의 영역을 compensate(보상)하기 위해 스케일링 계수에 적용
* 선형 보간법 : 끝점의 값이 주어졌을 때 그 사이에 위치한 값을 추정하기 위하여 직선 거리에 따라 선형적으로 계산하는 방법
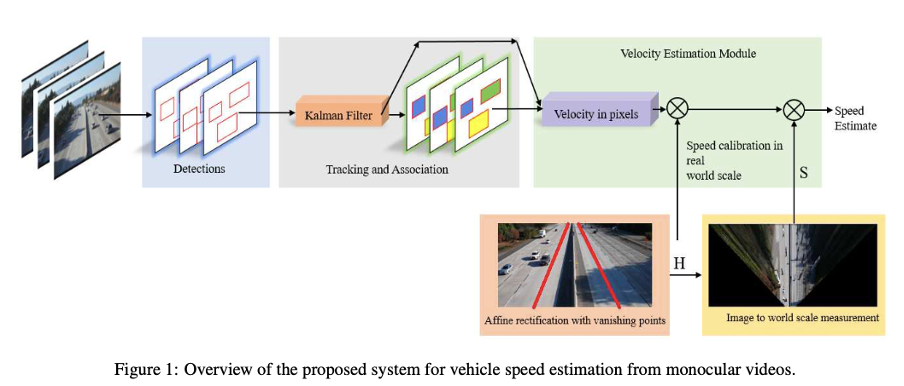
- 요약하자면, 이 연구의 주요 기여는 카메라 보정 및 레이저와 LIDARS를 사용하여 3D 거리 측정과 같은 값비싼 단계가 필요하지 않은 반자동 차량 속도 추정 접근법을 제안하는 것.
- NVIDIA AI City Challenge의 트래픽 속도 분석 데이터 세트의 경우 제안된 프레임워크는 9.54mph의 RMSE를 달성
Relation Works
- 차량 속도 추정에서 가장 어려운 것은 이미지 영역에서 측정한 것을 실제 세계의 metric과 연관시키는 것.
- 이전 연구를 카메라 보정이 필요한 방법(감시 카메라의 고유, 외적 매개변수 획득)과 이미지 영역에서 3D세계로 변환을 직접 추정하는 방법으로 분류
- [2,8,12]와 같은 대부분의 접근 방식은 이미지 평면과 3D 세계 사이의 정확한 포인트 대응에 대한 지식을 가정하여 카메라 매개 변수를 추정한다.
- 다른 방법 [3, 5]는 카메라를 보정하기 위한 3D 모델과 차량 움직임을 기반으로 합니다. [3, 4]는 카메라 보정을 위해 평균 차량 치수를 사용하기 때문에 완전 자동이다.
- [18] 카메라 보정을 위해 차량에 3D 바운딩 박스를 정렬합니다.
- 그러나 차량의 형태에 대한 사전 지식이나 도로에서의 광범위한 거리 측정 없이는 이러한 접근방식을 적용할 수 없다.
- [7]에서 작성자는 카메라가 도로와 수직인 축을 따라 기울어져 있다고 가정합니다. 사라짐 지점을 도로 축 방향으로 배치하여 이미지를 수리할 수 있습니다. 차량 추적 및 속도 추정은 정류된 이미지 영역에서 수행됩니다.
- Cathy와 Dailey[2]는 차량 이동 방향의 소멸 지점을 감지하는 방법을 사용했다. 이 소멸 지점은 least squares adjustment(최소 제곱 조정)과 선 표시의 intersection(교차점)으로 감지된다. 카메라의 스케일(픽셀/미터 비율)은 실제 세계에서 알려진 스트라이프 길이와 평균 라인 마킹에서 계산된다.
- 본 연구에서는 이미지 도메인에서 3D 세계로의 변환이 구글 맵의 수정 및 사전 지식으로 측정되는 위의 두 가지 접근 방식을 조합하여 사용한다.
Proposed Approach
제안된 차량 속도 추정 시스템은 (1) 차량 감지 (2) 추적 (3) 속도 추정의 세 가지 요소로 구성
(1) Vehicle Detection

- 차량의 위치를 알아내기 위해 Faster R-CNN의 확장모델인 Mask R-CNN 사용
- Mask-RCNN은 Faster R-CNN의 원래 분류 및 경계 상자 회귀 네트워크 외에도 각 관심 영역(RoI)에 대한 분할 마스크를 예측하기 위해 다른 분기를 추가한다.
- 이는 pixel-level segmentation mask(픽셀 레벨 분할 마스크)를 예측하기 위해 각 RoI에 소형 완전 컨볼루션 네트워크(FCN)를 적용하여 수행된다.
- 탐지 및 분할에 대한 공동 학습을 통해 마스크 R-CNN은 신뢰할 수 있고 엄격한 경계 상자로 차량의 위치를 지정할 수 있다.
- 우리는 Mask-RCNN이 다양한 규모로 차량을 감지할 수 있다는 것을 관찰하며, 이는 이미지의 어떤 규모로든 차량이 나타날 수 있기 때문에 이 과제에 crucial(중요)하다.
- 추적 및 속도 추정 모듈은 마스크-RCNN의 경계 상자를 사용.
(2) Tracking
- 우리는 두 가지 다른 추적 알고리듬을 비교하고 대조함 : SORT 와 DeepSORT
- Noteworthy(주목할 점)은 추적에 SORT와 DEEPSORT를 사용하는 주된 장점은 추적과 함께 픽셀 속도를 jointly(공동으로) 추정할 수 있다는 것이다.
- SORT
- 칼만 필터를 사용하는 모든 프레임에서 탐지를 associates(연관)시킨다. 특히 SORT는 linear Gaussian state space model(선형 가우스 상태 공간 모델)을 사용하여 각 대상 차량의 역학을 approximates(근사화)한다.
- Target의 상태 모델링 :

수식 (1) - x와 y는 경계상자 하단 중앙 좌표의 수평 및 수직위치 나타내고, s와 r은 경계상자의 영역과 가로비율을 각각 나타냄
- 탐지가 대상에 연결되면 탐지된 경계 상자가 대상의 상태 벡터를 업데이트하는 데 사용
- DeepSORT
- Target의 상태 모델링

수식(2) - x, y, r은 SORT와 뜻 같음, h는 경계상자의 높이를 나타냄.
- 하단 두 모서리의 중심을 추적한다. 이 지점들은 지면 면과 가깝고 섹션 3.3(speed estimation)에 제시된 아핀 변환에 따라 왜곡의 양이 가장 적기 때문
- x’와 y’은 차량의 속도를 approximate(근사화)하는데 사용
- SORT와 DeepSORT에서의 Data Association(데이터 연관/연결)
- SORT와 DeepSORT의 주요 차이점은 Data Association을 수행하는 방법
- SORT : 각 대상에 대한 새 경계 상자 위치는 Kalman Filter에 의해 예측, 그런 다음 assignment cost(할당 비용)은 각 탐지와 존재 대상의 모든 예측 경계 상자 사이의 intersection-over-union(IOU)으로 계산된다. (실제box와 예측box)
assignment(할당)은 Hungarian Algorithm을 사용하여 최적으로 해결됨. 또한, 탐지 및 대상 간의 겹침(IOU)이 최소값보다 작을 경우 할당을 거부하기 위해 최소 IOUmin이 imposed(부과됨)
- DeepSORT : 탐지된 각 경계 상자에 대해, appearance feature(외관 특성)은 pretrained CNN에 의해 추출됨. 각 추적에 대해 associated appearance features(연관된 외관 기능)의 갤러리(관련 정보)가 유지. 새로운 탐지는 코사인 거리가 가장 작은 트랙에 할당.
- 자세한 훈련 설정은 섹션 4.1에 표기
(3) Speed Estimation
- 이미지 영역의 Kalman Filter에서 픽셀 속도를 얻은 다음, 속도 추정 방식은 두 단계를 거침
1단계 : 장면의 affine-invariant properties(아핀 불변 특성)을 복원하기 위한 affine rectification(아핀 변환)
2단계 : 실제 환경에서 차량 속도를 추정하는 스케일 복구
- 3.3.1 Affine Rectification (아핀 변환)
- 교통 비디오는 보정되지 않은 카메라에 의해 촬영되므로 비디오의 각 프레임은 projective transformation(투영적 변환) 아래 이미지 평면에서 3D 세계를 projection(투영)하는 것입니다.
- 세그먼트 사이의 비율이 투영 변환에서 보존되지 않기 때문에 영상 영역에서 직접 속도를 추정하는 것은 어렵다.
- 본 연구에서, 우리는 대부분의 도로가 비행기를 통해 충분히 근사할 수 있다고 가정한다.
- 이러한 평면 영역의 경우 이미지 도메인의 점 x = [x, y, 1]T를 수정 도메인의 점 X = [X, Y, 1]T에 매핑하는 호모그래피 H를 추정하는 정류 기법을 적용한다.

- 비평면 지역은 속도 추정이 저하될 수 있으며, 이는 섹션 3.3.2에 제시된 스케일 복구에 의해 보상된다.
- H가 결정되면 (3)의 양쪽을 구별하여 정류된 영역의 속도를 얻을 수 있다.

- 여기서 Ci,j는 H에 해당하는 hi,j의 부수를 나타낸다.
- H를 추정하는 한 가지 고전적인 접근 방식은 두 가지 수직 방향에 대한 소멸 지점을 감지하는 것에 기초한다.
- 우리는 동종 좌표에서 두 개의 소멸 지점을 v1과 v2로 나타내며, 여기서 v1은 도로 축의 방향에 대응하고, v2는 v1에 수직인 방향에 대응한다.
- 다음 방정식은 그대로 유지됩니다.

- (3)의 파라미터는 (5) 및 (6)을 사용하여 해결할 수 있습니다. 각 위치에 대해 장면에서 점을 선택하여 두 개의 소멸 지점을 수동으로 감지합니다.
- 위치 1, 2, 3에서는 도로 축에 수직인 선이 영상 영역에서 거의 평행하기 때문에 이러한 위치에 대해 v2 = [0, 1, 0]T를 설정합니다.
- 3.3.2 Scale Recovery (스케일 복구)
- 섹션 3.3에서 제안된 이미지 수정은 비평면 영역을 왜곡시킬 수 있다.
- 따라서 이미지 수정 후 픽셀 공간에서 실제 영역으로 속도를 변환하려면 스케일을 복구하는 것이 중요하다.
- 이 복구는 수평 방향과 수직 방향으로 모두 수행해야 합니다.
- 우리는 수평 방향과 수직 방향의 스케일 복구를 위해 차선 폭과 도로 흰색 스트립 길이를 각각 사용한다.
- 구글 지도를 이용하여 우리는 실제 세계 거리의 대략적인 추정치를 얻었다.
- 수리 후 도로 차선이 평행이 되어 평면 영역에서 x 방향으로 일정한 차선 폭을 보장합니다.
- 따라서 x 방향의 스케일링 인자로 다음을 선택합니다.

- (7) W와 w는 각각 미터와 픽셀 단위로 실제 차선 폭을 나타냅니다.
- 수직 방향의 경우, 우리는 다른 접근법을 제안한다. 투영 및 보정 후에는 수직 방향을 따라 있는 픽셀이 늘어나며 이 효과는 감지된 소멸 지점 근처의 픽셀에서 더 두드러집니다.
- 따라서 y 방향을 따라 척도가 비선형적으로 변경됩니다. 이 척도 변동을 보상하기 위해, 우리는 다음과 같은 선형 보상자를 사용했다.

- 여기서 L1과 L2는 미터 단위에서 두 개의 서로 다른 높이에서 두 개의 흰색 스트립의 길이이다. l1과 l2는 변환된 이미지의 해당 길이이다.
- 마지막으로, 차량의 속도 추정치는 다음에 의해 제시됩니다.

- 이미지 공간의 높이가 ymin에서 ymax까지인 윈도우에 있는 모든 차량의 속도를 추정합니다.
Experimental Evaluations
- 이 섹션에서는 NVIDIA AI City Challenge Dataset에서 제안된 알고리듬을 평가한다.
- 우리는 먼저 추적 알고리듬에 대한 질적 및 정량적 평가를 수행한다.
- 그런 다음 단안 비디오에서 차량 속도 추정 결과를 보고한다.
(1) Implementation Details
- Vehicle Appearance Model(차량외관모델)
- DeepSORT에 대한 discriminative(차별적인) 차량 표현을 배우기 위해 세밀한 차량 식별 작업을 위한 DCNN을 학습시킴.
- 네트워크 구조는 Figure 3과 같음
- 우리는 163개의 자동차 makes(브랜드) 및 1,716개의 자동차 모델에 대한 136,726개의 이미지로 구성된 CompCar 데이터 세트에서 네트워크를 훈련
- 배치 크기 128로 훈련, 학습률은 0.01, 50K(50,000번) 반복 후 절반으로 줄어듭니다.
- Vehicle Detector (차량 탐지 모델)
- 우리는 MS-COCO 데이터 세트에 대해 훈련된 Detectron[6]에 구현된 Mask-RCNN을 사용한다[15].
- 특징 피라미드 네트워크[14]와 ResNet-101(Backbone)을 기반으로 한다.
(2) Evaluation Metric (평가기준)
- 차량 속도 추정의 성능은 S1 측정 기준을 사용하여 계산한다.

- DR과 NRMSE은 respectively(각각) other participating teams(다른 참가 팀)과 비교하여 검출 속도와 정규화된 루트 평균 제곱 오차(RMSE)를 나타냄
- DR은 감지된 차량과 ground truth vehicle(실제 차량) 사이의 비율로 정의됩니다
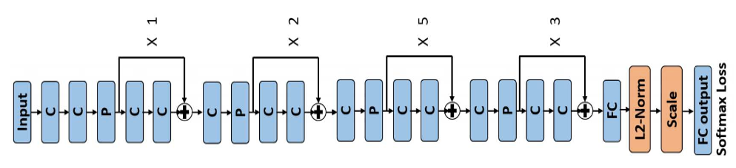
Figure 3 : C는 Convolution Layer(PReLU), P는 Max Pooling Layer 나타내며, 각 풀링 계층 다음에는 일련의 잔여 연결이 뒤따름(Skip Connection)
residual connections(잔여 연결)의 수는 함께 표시. 그 뒤에 완전연결층 거치며,
L2-정규화층과 스케일층이 추가되고 그 뒤에 Softmax-Loss층이 추가됩니다.

Figure 4 : SORT와 DeepSORT의 추적결과 Comparison(비교)
(a) SORT에서 추적객체 몇 프레임 후에 손실되고 다시 초기화
(b) DeepSORT는 추적객체을 잃지 않고 효과적으로 차량을 추적할 수 있습니다.
(평가지표 생략)
Conclusion and Future Work
- 본 논문에서는 단안 비디오에서 차량 속도 추정을 위한 반자동 시스템을 제시하였다.
- 제안된 접근 방식은 명시적 카메라 보정 및 차량 또는 건물에 대한 3D 모델링 없이 속도를 신뢰성 있게 추정할 수 있다.
- 향후 연구를 위해 키포인트 감지 및 추적 기능을 파이프라인에 통합하여 속도 측정을 개선할 수 있습니다.
'Minding's Reading > 논문읽기' 카테고리의 다른 글
| [SORT]SIMPLE ONLINE AND REALTIME TRACKING (0) | 2021.03.11 |
|---|