실시간으로 다중 객체 추적을 할 수 있으며,
간단한 원리로 연산량을 줄여 속도와 정확성이 비교적 높은 객체추적 알고리즘이다.
Computer Vision Tracking에 최근 관심을 가지게 되어,
DeepSort 논문을 읽기전 SORT를 먼저 읽어보게 되었다.
Paper link : arxiv.org/abs/1602.00763
Simple Online and Realtime Tracking
This paper explores a pragmatic approach to multiple object tracking where the main focus is to associate objects efficiently for online and realtime applications. To this end, detection quality is identified as a key factor influencing tracking performanc
arxiv.org
● Abstract (초록)
- 다중 객체추적 (Multiple Object Tracking)을 위한 실용적 접근
- 온라인, 실시간으로 객체들을 효율적으로 연관시키는 데 초점
- Detection quality는 Tracking 성능에 영향을 끼치는 중요 요소 (Detector만 잘 설정해도 18.9%까지 성능 향상)
- Detection 구성요소로 Kalman Filter와 Hungarian Algorithm 조합
(고전적인 기술 사용에도 최신 Tracker들과 비슷한 성능)
- 추적기법 단순하여 다른 Tracker보다 20배 이상 빠름
● 1. Introduction
- 다중객체추적(MOT)을 위해 검출에 의한 추적(tracking-by-detection) 프레임워크 구현 방법 제안
- 여러 배치(batch)기반 접근들과 대조적으로, 이전 및 현재 프레임의 검출결과만
tracker에 제공되는 온라인 추적이 주요대상
- 실시간 추적 효율성에 초점을 두어 보행자 추적 등 Application의 성능 증진
- MOT문제는 video sequence의 여러 프레임에서 detection을 연관시키는 것이 목적인
Data Association 문제
- Data Association을 위해 Tracker는 Object의 움직임과 appearance를 모델링하기 위해 다양한 방법론 사용
- Aggregate Channel Filter(ACF) detector를 사용하지 않은 tracker가 최상의 tracker인 것을 보아,
detection quality가 tracker를 방해할 수 있음
- 정확한 Tracker들의 속도는 매우 느리기 때문에 실시간 Application에 적용이 불가능
- (Figure 1) 정확도 - 속도 간 Trade-off 관계 명확
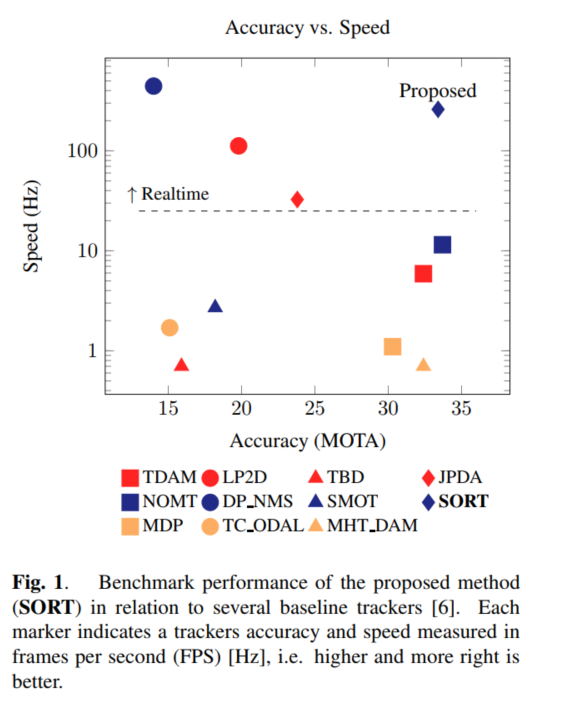
→ 가장 좋은 (최신의) Online / Batch tracker들 사이에서 전통적인 데이터 연관기법이 부각됨에 따라,
MOT를 단순하면서도 잘 할 수 있는 지에 대해 연구
- 오캄의 면도날(Occam's Razor) 1에 의해, 추적 시에는 검출 구성요소 이외의 appearance features는 무시하고, 바운딩 박스 위치와 크기만이 움직임 추정 및 데이터 연관을 위해서 사용됨
- short-term 또는 long-term 가려짐에 대한 문제도 무시됨. 이는 매우 드물게 발생하고 문제해결 처리를 위해서
framework에 원치않는 복잡성을 만들기 때문
- 객체를 재식별(re-identification)하는 형태라면, 추적 framework에 상당한 비용 추가되어
실시간 Application 사용에 제약이 있다고 판단
- 다양한 edge cases와 detection errors를 처리하기 위해 다양한 구성요소를 통합시킨 visual tracker들과
대조적으로, 일반적인 frame-to-frame 연관을 효율적이고 신뢰할 수 있도록 다루는 데 초점을 둠
- Detection errors에 대한 견고성보다는 visual objcet detection의 최근 발전을 이용해 해결
(ACF 검출기와 CNN기반 검출기 비교하여 입증가능)
- 추가적으로, 고전적이지만 효율적인 두 가지 방법 Kalman Filter와 Hungarian method를 적용하여
motion prediction과 data association 구성요소를 처리함.
→ 최소한의 tracking 공식으로 Online Tracking을 위한 효율성과 신뢰성 확보
- 다양한 환경의 보행자를 추적하기 위해 연구되었으나, CNN 기반 detector의 유연성으로
다른 object classes에도 일반화 가능
* The main contributions of this paper (연구의 주요 기여점)
- MOT의 맥락에서 CNN기반 검출(detection)을 활용
- Kalman Filter와 Hungarian Algorithm 기반 실용적 접근 제안하였고, 최근 MOT benchmark에 대해 평가
- 연구실험을 위한 baseline을 확립에 도움을 주기위해 코드를 공개할 것이며,
충돌 회피 Application에 활용할 수 있음
● 2. Literature Review(문헌 검토)
- 전통적으로 다중 객체 추적은 MHT(Multiple Hypothesis Tracking) 또는 JPDA(Joint Probabilistic Data Association)필터사용했으나 이는 객체 할당에 높은 불확실성이 있는 경우 어려운 결정을 지연시킴
- 이러한 접근법의 조합 복잡도는 추적 객체의 수를 기하급수적으로 증가시켜 높은 동적 환경안의
실시간 Application에서는 실용적이지 않음
- 최근 [2]에서, 정수 프로그램 해결의 최근 개발을 이용하여 JPDA의 효율적인 근사치를 구함으로써,
조합복잡도 문제를 해결하기 위해 Visual MOT에서 JPDA 공식을 재검토 하였음
- 비슷하게, [3]에서는 최고의 성능을 달성하기 위해, 각 target의 MHT graph 가지치기(prune)하는
appearance model 사용
- 그러나, 이 방법들은 여전히 decision making을 지연시켜 online tracking에는 부적합
- 많은 Online tracking 방법론들은 Online learning을 통해 개별 객체 자신 또는 global model에 대한
appearance model을 만드는 것을 중점으로 함
- appearance model 외에, 움직임(motion)은 종종 tracklet2에 대한 detection을 지원하기 위해 통합됨
- 이분(bipartite)그래프 매칭으로 모델링되는 one-to-one 관련성을 고려할 때,
Hungarian Algorithm과 같은 전역 최적 솔루션(globally optical solution) 사용 가능
- [20]에서 Hungarian Algorithm을 두 단계 과정으로 사용
1단계 : geometry와 외관 단서(appearance cues)들을 결합하여 유사도 행렬(affinity matrix)을 만들고
detections과 인접프레임들을 연관지어 tracklets를 형성
2단계 : 가려짐에 의해 손상된 궤도(trajectories)3를 연결하기 위해
다시 geometry와 appearance cues를 사용해 tracklet들은 서로 연결되어짐
- 두 개의 단계로 구성된 association기법은 이러한 접근을 batch compuation(계산)으로 제한시킴
본 연구는 [20]에서 영감을 얻었지만, 기본적인 cue들만 이용하여 association을 한 단계로 단순회시킴
● 3. Methodology (방법론)
- 제안한 방법은
[detection의 구성요소] / [다음 프레임으로 객체 상태 전파] /
[현재 detection과 기존 객체들의 association] / [추적된 객체들의 수명(lifespan)의 관리] 로 설명됨
3.1 Detection (검출)
- CNN기반 detection의 빠른 발전을 이용하기 위해, FrRCNN4 detection framework 사용
- FrRCNN은 end-to-end framework5로, 2단계로 구성됨
1단계 : 특징 추출(extracts features)과 영역 제안(proposes region)
2단계 : 위에서 제안된 영역 내에서 Object Classification
- FrRCNN framework의 장점
1. detection을 위한 효율적인 framework를 만들 때 두 단계 사이 parameters를 공유
2. 또한, detection 성능 개선을 위해 다른 architecture를 이용한 빠른 실험이 가능하도록, Network Architecture가
다른 어떠한 설계의 Architecture로 교체 가능
- 본 연구에서는 FrRCNN과 함께 제공된 두 가지 Network Architecture인 Zeiler와 Fergus의 Architecture(FrRCNN(ZF)와Simonyan과 Zisserman의 심층(deeper) Architecture(FrRCNN(VGG16)을 비교함
* backbone : ZFNet, VGG16
* parameters : PASCAL VOC를 위해 학습된 기본 파라미터
- 보행자를 검출하는 것에만 관심이 있으므로, 다른 클래스를 모두 무시하며 검출 결과 사람일 확률 50% 이상에만
tracking framework를 넘겨줌
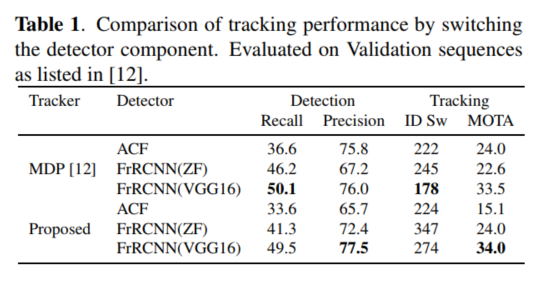
- FrRCNN과 ACF를 비교하는 실험에서, detection quality가 tracking에 큰 영향을 준다는 것을 발견
- 기존 온라인 추적기 MDP와 연구에서 제안된 추적기에 같은 validation set 사용해 입증
- FrRCNN(VGG16)이 MDP와 제안된 추적기 모두에서 가장 높은 정확도
3.2 Estimation Model (모델 평가)
- 객체 모델은 target의 ID를 다음 프레임으로 전파하기 위해 사용되는 표현모델과 움직임(motion) 모델
- 다른 객체 및 카메라 움직임과 독립적인 선형 등속 모델(linear constant velocity model) 사용하여
각 객체의 프레임 간 변위 근사화
- 각 객체의 state(상태)는 아래와 같이 모델링 됨

u = Target의 중심기준 픽셀의 가로위치
v = Target의 중심기준 픽셀의 세로위치
s = Target의 bounding box의 scale(area, 면적)
r = Target의 bounding box의 종횡비 (참고 : 일정하게 고려됨)
- Detection이 target과 연결된 경우, 검출된 bounding box는 Kalman Filter를 통해 속도 구성요소를 최적화하여
Target의 상태를 업데이트
- Detection과 target이 연결되지 않은 경우, 선형 속도 모델 사용하여 수정(correction) 없이 상태 예측
3.3 Data Association (데이터 연관)
- 기존 target에 detection을 할당함에 있어, 각 target의 bounding box의 기하학(geometry)은 현재 프레임에서
새 위치를 예측하여 수정
- 할당 비용 행렬 (assignment cost matrix)은 각 detection과 기존 target에서 예측된 모든 bounding box 사이의
IOU(intersection-over-union)거리 이용하여 계산
- 할당(assignment)은 Hungarian Algorithm 사용하여 최적으로 해결
- 또한, detection과 target의 중첩 영역이 IOUmin보다 작을 경우 할당 거부 → 이럴 경우 IOUmin 적용
- 지나가는 target에 의해 야기되는 짧은 가려짐을 bounding box의 IOU거리를 통해 암시적 처리 가능하다는 것 발견
- 구체적으로, target이 다른 객체에 가려져 있을 때, IOU거리가 유사한 척도의 탐지를 적절히 선호하기 때문에
가려짐을 야기한 객체만 검출 가능
- 이러면, 덮힌 객체는 할당되지 않아 영향을 받지 않고, 가려짐을 야기한 객체와 함께 두 tartget 모두 수정가능
3.4 Creation and Detection of Track Identities (추적 ID의 생성과 삭제)
- Image에서 객체가 통과되거나 떠날 때, 각 ID는 적절히 만들어지거나 파괴되어야 함
- Tracker 생성에 있어, 우리는 추적되지 않은 객체의 존재를 나타내기 위해 IOUmin보다 작은 중첩을 가진
모든 detection을 고려해야 함
- Tracker는 속도가 0으로 설정된 상태에서 bounding box의 geometry를 이용해 초기화 됨
- 이 시점에서는 속도가 관찰되지 않으므로 속도 성분의 공분산(covariance)은
불확실성 반영하여 큰 value로 초기화
- 또한, 새 tracker는 false positive(가긍정적 판단)의 추적을 막기 위해 target과 detection들을 연관시켜
충분한 증거를 모으게 하는 수습기간을 가짐
- TLost frame에서 Detection이 없다면 Track들은 종료
- 이는 Detector로 부터 장기간 동안 보정없는 prediction에 의해 야기되는 tracker들의 수가
무한히 증가되는 문제와 localization error를 막기 위한 것
- 모든 실험에서 TLost는 1로 설정함(2가지 이유때문)
1. 등속모델 (constant velocity model)은 실제 역학(dynamics)에 대해 불충분한 predictor임
2. frame-to-frame 추적에만 관심있으며, 객체 재식별(re-identification)을 하는 것은 연구 범위 밖
- 또한, 손실된 target의 조기 삭제는 효율성에 도움이 됨
- 객체가 다시 나타나면 새로운 ID에서 추적이 암시적으로 재개
● 4. Experiments (실험)
- 이동 및 정적 카메라 시퀸스를 모두 포함하는 MOT benchmark 데이터베이스의 다양한 테스트 시퀸스에 대한
tracking 구현 성능을 평가
- 초기 Kalman Filter의 공분산(covariance), IOUmin, TLost의 parameter 조정을 위해
[12]와 동일한 training / validation set 분할 사용
- Detection Architecture는 FrRCNN(VGG16)
- [22]의 소스코드 및 샘플 detection은 Online으로 사용가능
4.1 Metrics(지표)
- 단일 점수 사용하여 Multitarget tracking 성능을 평가하는 것은 어려우므로,
표준 MOT Metrics와 [24]에 정의된 평가 metrics 사용
≫MOTA(↑) : Multi-object tracking accuracy[25]
≫MOTP(↑) : Multi-object tracking precision[25]
≫FAF() : number of false alarms per frame
≫MT() : number of mostly tracked trajectories (target 수명의 최소 80%에 대해 동일 label 가지는 경우)
≫ML() : number of mostly lost trajectories (target 수명의 최소 20% 동안 추적되지 않은 경우)
≫FP() : number of false detections
≫FN() : number of missed detections
≫ID sw() : number of times an ID swiches to a different previously tracked object
(ID가 이전에 추적된 다른 객체로 전환되는 횟수)
≫Frag() : number of fragmentations where a track is interrupred by miss detection
(오탐지로 인해 tracking이 중단되는 파편의 수)
- Ground Truth(지상 실측 정보)6 바운딩 박스와 중첩 영역이 50% 이상인 경우에만 True Positive로 고려
- 평가 코드는 [6]에서 다운로드 가능
4.2 Performance Evaluation (성능 평가)
- 추적 성능은 MOT benchmark 테스트 서버의 11개 시퀸스에 대해 평가 진행
- 가장 빠른 batch tracker(DP_NMS[23]), 정확성 제일 좋은 Online Tracker(TDAM[18], MDP[12]),
All round near online method(NOMT[11])와 영감을 준 방법론(TBD[20], ALExTRAC[5], SMOT[1])들과 비교
- 제안된 방법 SORT는 Online tracker들 중 가장 높은 MOTA score 기록
- 이 성능은 훨씬 복잡하고 가까운 미래 프레임을 사용하는 최신 기술 NOMT와도 견줄 만 함
- SORT는 frame-to-frame 연관(association)에 초점을 두기 때문에, 다른 tracker들과 비교해
비슷한 false negative를 가지면서도 잃어버린 target(ML)은 최소 기록
- SORT는 tracklet 증가를 위해 frame-to-frame 연관에 초점을 두므로, 다른 방법과 비교해
손실된 target의 수가 가장 적음

4.3 Runtime (런타임)
- 대부분의 MOT 방법들은 런타임 성능 희생시켜 더 높은 정확도 성능을 만드는데 초점을 둠.
오프라인 작업에서는 허용될 수 있으나, 로봇 공학이나 자율 주행에서는 실시간 성능이 필수적
- Figure 1에서 볼 수 있듯, 속도와 정확도는 여러 tracker들의 성향을 보여줌
최고의 정확도를 보여주는 방법은 속도가 가장느리며, 최고의 속도를 보여주는 방법은 정확도가 낮은 경향을 보임
(각각 Fig 1의 우하단과 좌상단)
- SORT는 전형적 단점없이 속도와 정확도의 두 가지 바람직한 속성 결합 가능 (Fig 1의 우상단)
- 추적요소는 Intel i7 2.5GHz와 16GB 메모리에서 260Hz로 동작
● 5. Conclusion (결론)
- 본 논문에서는 프레임 간 예측 및 연관성에 초점을 맞춘 간단한 온라인 tracking framework 제시
- Tracking quality이 Detection quality에 크게 좌우된다는 것을 보여줌
- 최근 Detection의 발전을 이용해, 고전적 tracking방법만으로 뛰어난 tracking quality 달성
- 제시된 framework는 속도와 정확도 모두에 대해 최고성능을 달성한 반면, 다른 방법은 일반적으로 둘 중 하나 희생
- 제안한 fromework의 단순성은 baseline(기준)이 되기에 적합하여 장기간 가려짐을 처리하기 위한
객체 재식별에 초점을 두는 새로운 방법 적용가능
- 본 연구에서 Tracking에 있어 detection quality의 중요성을 강조함에 따라, 향후 연구는 밀접히 결합된
detection 및 tracking framework 연구할 것
- 현상을 설명할 때 불필요한 가정을 하지 않는 것, 간단하게 현상을 설명하는 것이 더 옳은 주장이라고 정의 [본문으로]
- 검출한 n개의 detection결과를 유사도 기준에서 가장 유사도가 큰 객체의 ID값을 유지하는 작업 [본문으로]
- 어떤대상의 전체구간 경로, tracklet들 간 유사도를 계산하여 이들을 이어붙이는 방식 [본문으로]
- FR-CNN에 비해 Region Proposal 단계에서 bottleneck 현상 제거한 모델 [본문으로]
- 모델의 모든 파라미터가 하나의 손실함수에 대해 동시 훈련, 입력(end)과 출력(end)을 직접 고려하여 네트워크 가중치 학습, Data가 많고 Labeling이 된 경우 잘 작동함. [본문으로]
- 데이터의 label값을 가르키기도 함. [본문으로]