OmniParserV2
OmniParserV2는 Microsoft에서 개발한 컴퓨터 비전(모델은 YOLO) 기반 GUI 자동화 도구로, 사용자의 UI 스크린샷을 구조화된 데이터로 변환해 LLM이 구조를 이해하고 상호작용할 수 있도록 돕는다. 이 도구를 통해 LLM과의 상호작용을 통해 GUI 테스트 등을 자동화할 수 있다.
아직은 실제 클릭과 같은 경우는 사용자의 판단이 필요하거나, 유해 콘텐츠 필터링 기능이 제공되지 않는 한계점이 존재하지만, OmniParserV2와 같은 도구를 통해 SW의 UI 테스트를 자동화하거나, 반복되는 업무를 자동화할 수 있을 것으로 기대된다.
OmniParserV2의 특징
- 상호작용 요소 탐지 및 분석: UI 스크린샷에서 클릭 가능한 버튼, 아이콘 등을 감지할 수 있고, 해당 요소의 의미를 파악해 LLM이 이를 파악할 수 있도록 한다.
- 성능 향상: 이전 모델에 비해 분석 속도를 최대 60% 단축했고, ScreenSpot Pro 벤치마크에서 39.6%의 정확도를 기록했다.
- 다양한 OS에서 사용 가능: Windows, macOS, Linux, iOS, Android의 다양한 OS와 App에서 사용 가능하다.
- 오픈소스: 일부 모델(icon_detect)을 제외한 모든 소스는 오픈 소스로 제공되어 자유롭게 사용 가능하다.
OmniParserV2 사용해보기
OmniParserV2 설치 및 세팅
OmniParserV2는 LLM과 CV 모델을 로컬에서 돌리는 만큼 GPU에 대한 기본 세팅이 필요하다. NVIDIA 드라이버와 CUDA 설치가 필요한데, 이 글에서는 다루지 않으니 미리 세팅해놓도록 하자.
MS의 OmniParserV2 공식 Github에 접속해 git clone 명령어를 통해 소스코드를 다운로드받는다.
git clone https://github.com/microsoft/OmniParser.git
이후 해당 페이지에서 안내하는대로 새로운 가상환경을 만들고, 종속성 라이브러리를 설치한다. (공식 안내에서는 conda를 사용한다.)
cd OmniParser
conda create -n "omni" python==3.12
conda activate omni
pip install -r requirements.txt
그 다음 OmniParserV2 모델에서 사용할 weights를 아래 명령어를 통해 다운로드받는다.
# download the model checkpoints to local directory OmniParser/weights/
for f in icon_detect/{train_args.yaml,model.pt,model.yaml} icon_caption/{config.json,generation_config.json,model.safetensors}; do huggingface-cli download microsoft/OmniParser-v2.0 "$f" --local-dir weights; done
mv weights/icon_caption weights/icon_caption_florence여기까지 했다면 OmniParserV2를 실행할 기본적인 세팅은 끝났다.
Demo 사용해보기
gradio_demo.py를 실행시키면 OmniParserV2의 화면 인식을 데모 버전으로 실행시켜볼 수 있다.
python gradio_demo.py
기본적으로 http://0.0.0.0:7861/ 링크를 통해 데모 페이지를 열어볼 수 있다.

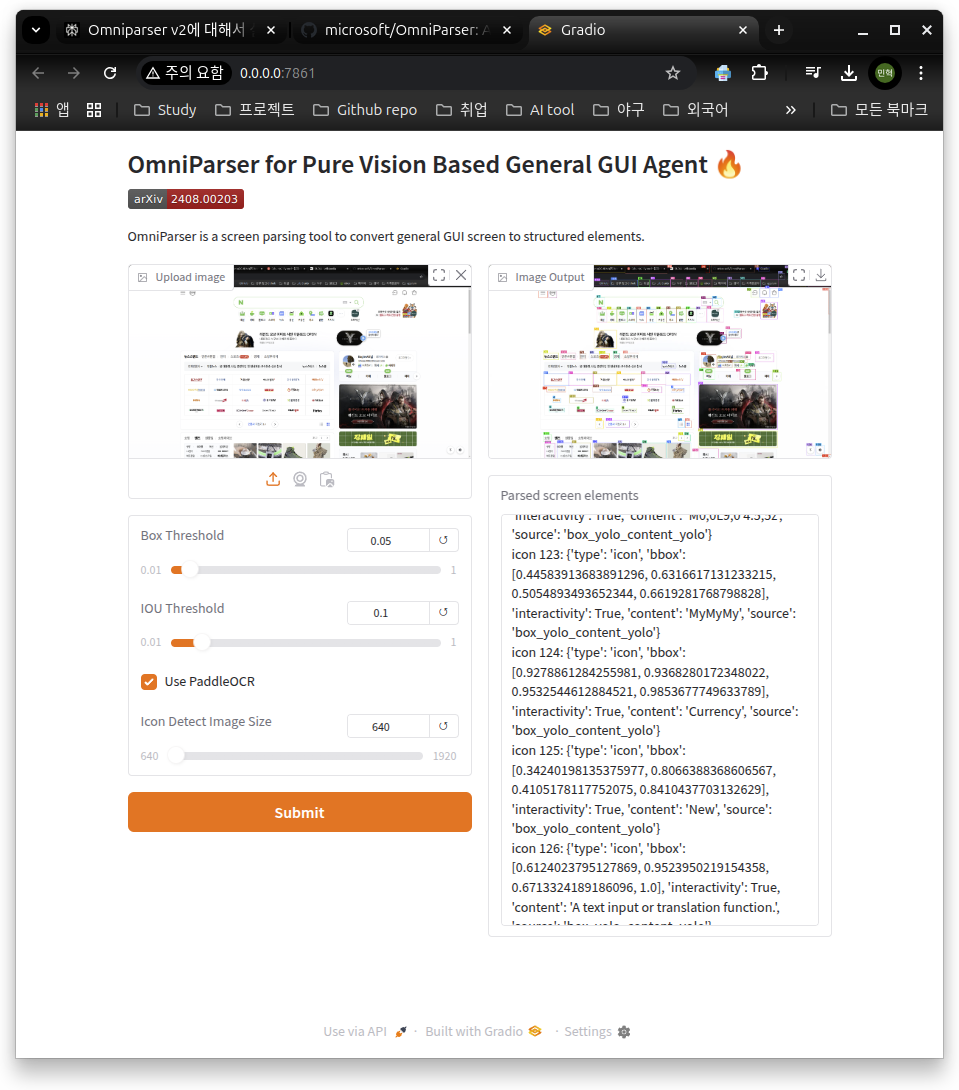
좌측 상단의 Upload Image를 통해서 스크린샷 이미지를 업로드할 수 있고, 해당 스크린샷을 기반으로 OmniParserV2가 작동해 화면의 각 요소들을 탐지하는 방식이다.
세부 설정으로는 4가지 정도를 설정할 수 있는데 각 설정에 대한 설명은 아래와 같다.
- Box Threshold: 객체 탐지에 사용하는 예측 Bounding Box의 유효성을 검증하는 기준(임계)값을 의미한다.
- IOU Threshold: 예측된 바운딩 박스와 실제 객체 위치 간의 겹치는 비율로, 해당 값이 높을수록 겹치는 비율이 높아야만 예측이 정확하다고 판단한다.
- Use PaddleOCR: 이미지나 문서에서 텍스트를 인식하고 추출하는 데 사용하는 PaddleOCR의 사용여부를 선택할 수 있다.
- Icon Detect Image Size: Input으로 주어지는 스크린샷의 사이즈로, 값이 높을수록 세세한 탐지가 가능하지만 속도가 느려질 수 있다.
네이버의 메인 화면을 스크린샷한 뒤 업로드해보았다. 결과는 다음과 같이 나왔다. 완벽하진 않지만 거의 모든 요소에 대한 인식을 성공한 모습이 보인다.
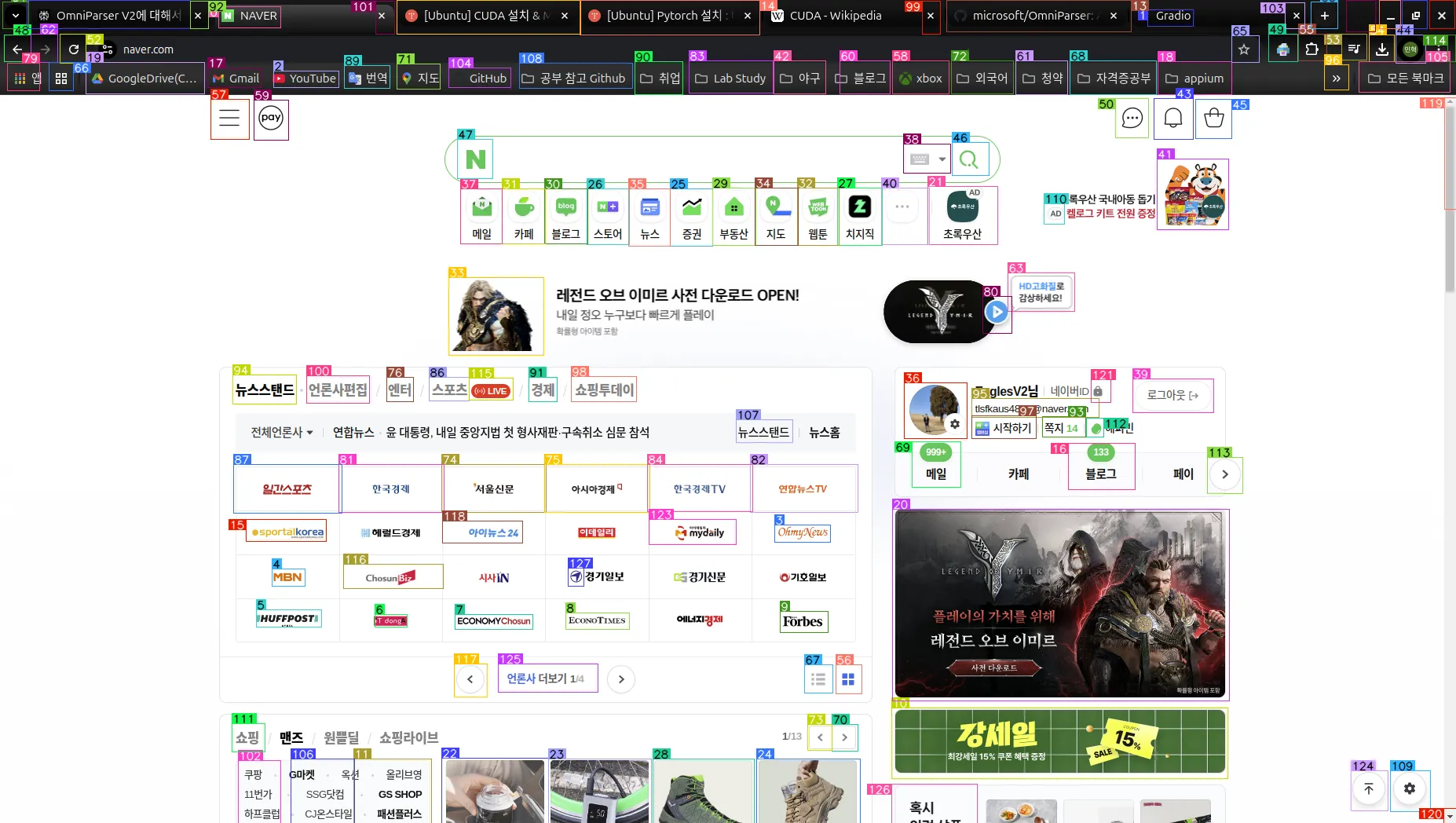
위 화면에서 인식된 데이터는 아래와 같이 출력되기도 한다.
icon 0: {'type': 'text', 'bbox': [0.14994606375694275, 0.007633587811142206, 0.19255663454532623, 0.033396948128938675], 'interactivity': False, 'content': 'NAVER', 'source': 'box_ocr_content_ocr'}
icon 1: {'type': 'text', 'bbox': [0.7885652780532837, 0.011450381949543953, 0.8198489546775818, 0.03148854896426201], 'interactivity': False, 'content': 'Gradio', 'source': 'box_ocr_content_ocr'}
icon 2: {'type': 'text', 'bbox': [0.1877022683620453, 0.08683206140995026, 0.2324703335762024, 0.10687022656202316], 'interactivity': False, 'content': 'D YouTube', 'source': 'box_ocr_content_ocr'}
icon 3: {'type': 'text', 'bbox': [0.5323624610900879, 0.6374045610427856, 0.5706580281257629, 0.6583969593048096], 'interactivity': False, 'content': 'OhmyNews', 'source': 'box_ocr_content_ocr'}
icon 4: {'type': 'text', 'bbox': [0.18662351369857788, 0.6908397078514099, 0.20927724242210388, 0.7118320465087891], 'interactivity': False, 'content': 'MBN', 'source': 'box_ocr_content_ocr'}
icon 5: {'type': 'text', 'bbox': [0.17583602666854858, 0.7404580116271973, 0.2206040918827057, 0.7614504098892212], 'interactivity': False, 'content': 'IHUFFPOSTI', 'source': 'box_ocr_content_ocr'}
icon 6: {'type': 'text', 'bbox': [0.2572815418243408, 0.7461832165718079, 0.2793959081172943, 0.7614504098892212], 'interactivity': False, 'content': 'iT dongA', 'source': 'box_ocr_content_ocr'}
icon 7: {'type': 'text', 'bbox': [0.3122977316379547, 0.7461832165718079, 0.3656958043575287, 0.7643129825592041], 'interactivity': False, 'content': 'ECONOMYChOsun', 'source': 'box_ocr_content_ocr'}
icon 8: {'type': 'text', 'bbox': [0.3883495032787323, 0.7442747950553894, 0.4320388436317444, 0.7643129825592041], 'interactivity': False, 'content': 'ECONOTIMES', 'source': 'box_ocr_content_ocr'}
...
icon 123: {'type': 'icon', 'bbox': [0.44583913683891296, 0.6316617131233215, 0.5054893493652344, 0.6619281768798828], 'interactivity': True, 'content': 'MyMyMy', 'source': 'box_yolo_content_yolo'}
icon 124: {'type': 'icon', 'bbox': [0.9278861284255981, 0.9368280172348022, 0.9532544612884521, 0.9853677749633789], 'interactivity': True, 'content': 'Currency', 'source': 'box_yolo_content_yolo'}
icon 125: {'type': 'icon', 'bbox': [0.34240198135375977, 0.8066388368606567, 0.4105178117752075, 0.8410437703132629], 'interactivity': True, 'content': 'New', 'source': 'box_yolo_content_yolo'}
icon 126: {'type': 'icon', 'bbox': [0.6124023795127869, 0.9523950219154358, 0.6713324189186096, 1.0], 'interactivity': True, 'content': 'A text input or translation function.', 'source': 'box_yolo_content_yolo'}
icon 127: {'type': 'icon', 'bbox': [0.39023855328559875, 0.6901223063468933, 0.4010043740272522, 0.7121850252151489], 'interactivity': True, 'content': 'Navigator', 'source': 'box_yolo_content_yolo'}'interactiviry'에는 해당 요소가 상호작용이 가능한지의 여부에 대해 제공하고, 'content'라는 칼럼에는 해당 요소의 의미를 해석한 모습이 보인다. 한글이 대부분이기 때문에 완벽하진 않지만, 생각보다는 괜찮은 성과를 보인다.
OmniTool 설치 및 세팅
Gradio demo를 통해 OmniParserV2가 제대로 동작하는 것을 확인했다면, 이제는 OmniTool을 이용해서 LLM과 상호작용 기능까지 사용해 볼 차례다. OmniTool을 사용하기 위해서는 몇 가지 설치 및 세팅이 추가로 필요하다. 공식 Github페이지를 참고해보자.
1. omniparserserver
위에서 OmniParserV2의 설치과정을 잘 따랐다면, 이 부분에서는 서버를 실행시켜주기만 하면된다. omniparser를 이용하기 위한 FastAPI 서버로, Web UI도 제공해준다.
cd OmniParser/omnitool/omniparserserver
python -m omniparserserver
2. omnibox
omnibox는 Docker 컨테이너에서 실행되는 Windows 11 VM(Virtual Machine)이다. 이를 위해 사전에 Docker Desktop 설치가 필요하다. 드라이브에 남은 공간이 30GB 이상 필요하니, 참고하자.
우선, Microsoft Evaluation Center에 접속해 자신의 OS에 맞는 Windows 11 Enterprise Evaluation (90-day trial, English, United States) ISO 파일을 다운로드 받아준다. 해당 파일은 custom.iso라는 이름으로 바꾼 뒤, OmniParser/omnitool/omnibox/vm/win11iso의 경로로 이동시켜준다.
그 다음, 아래 명령어를 통해 도커 이미지를 다운로드 받은 뒤 컨테이너를 빌드 및 ISO 파일을 통해 스토리지 폴더를 설치하는 스크립트를 실행시킨다. 여기엔 꽤 많은 시간이 소요된다. 공식 홈페이지에서는 일반적으로 1시간이 소요된다고 한다.
cd OmniParser/omnitool/omnibox/scripts
# 스크립트 실행
./manage_vm.sh create이 과정에서는 Progress Bar가 제공되지 않아 정상적으로 실행되고 있는지 알 수가 없는데, 아래 명령어를 통해 스토리지 폴더의 용량을 확인해 설치가 되고 있는지 정도는 확인할 수 있다. 10초마다 업데이트 되는데, 이 때 용량 변화가 있다면 정상적으로 실행되고 있다는 뜻이다.
watch -n 10 'du -sh ~/project/OmniParser/omnitool/omnibox/vm/win11storage'여기서 나는 개인적으로 에러를 발견했는데, 위 명령어를 통해 스토리지 용량을 지속적으로 확인해도 변함이 없었다. 그 이유는 docker container가 제대로 실행되지 않는 문제였다. 컨테이너는 omnibox 디렉토리 아래 compose.yml 파일을 실행시키는 것이었기 때문에 직접 실행해보았다. 해결 내용은 아래 접은 글을 참고하길 바란다.
cd OmniParser/omnitool/omnibox
# compose.yml 파일 직접 실행해보기
docker compose up위 명령어를 실행시켜 본 결과 노출된 메시지는 아래와 같았다.
ERROR: Your configured RAM_SIZE of 8 GB is too high for the 8 GB of memory available, please set a lower value.위 메시지는 docker desktop의 메모리 Resource 사용량 제한이 8GB인데, 해당 compose.yml 파일에 설정된 최소치 또한 8GB이기 때문에 더 낮은 값으로 재설정하라는 뜻이다. 나는 compose.yml 파일을 수정하기 보다는, docker desktop에서 메모리 허용량을 늘리는 방향으로 해결했다.
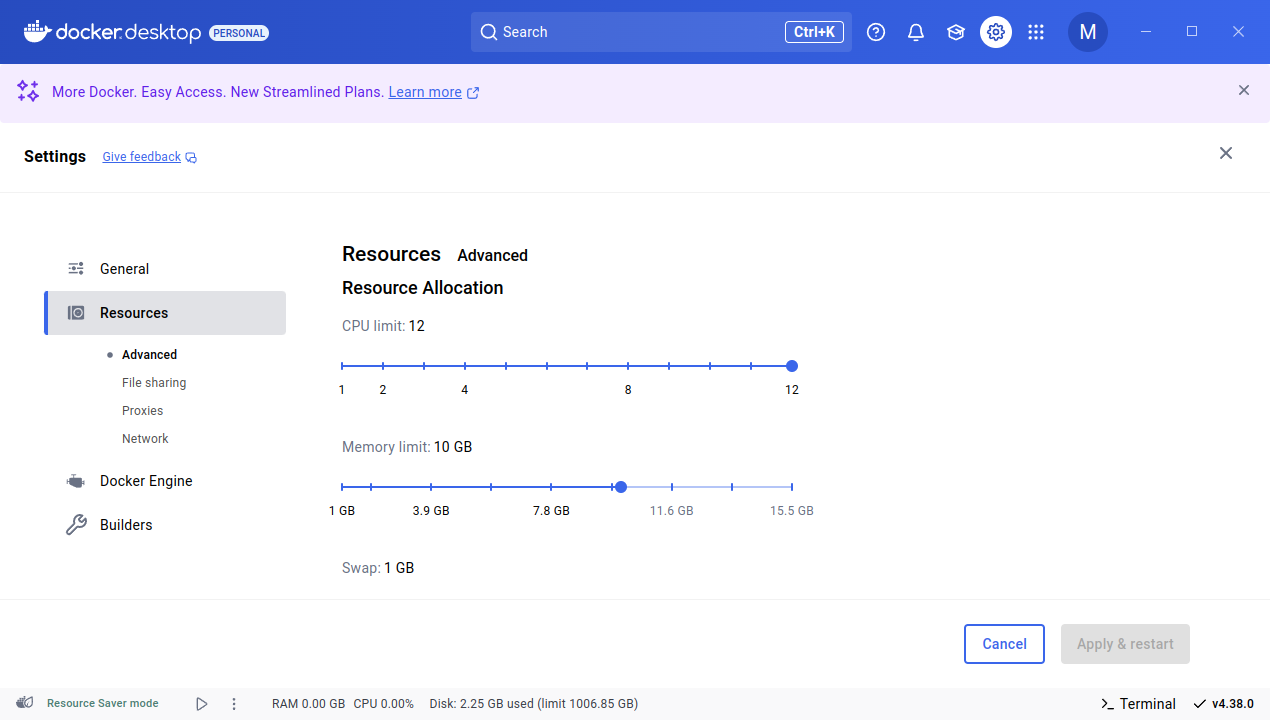
Settings > Resources > Memory limit을 10GB로 재설정한 뒤, 다시 manage_vm.sh create 명령어를 실행시켰다.
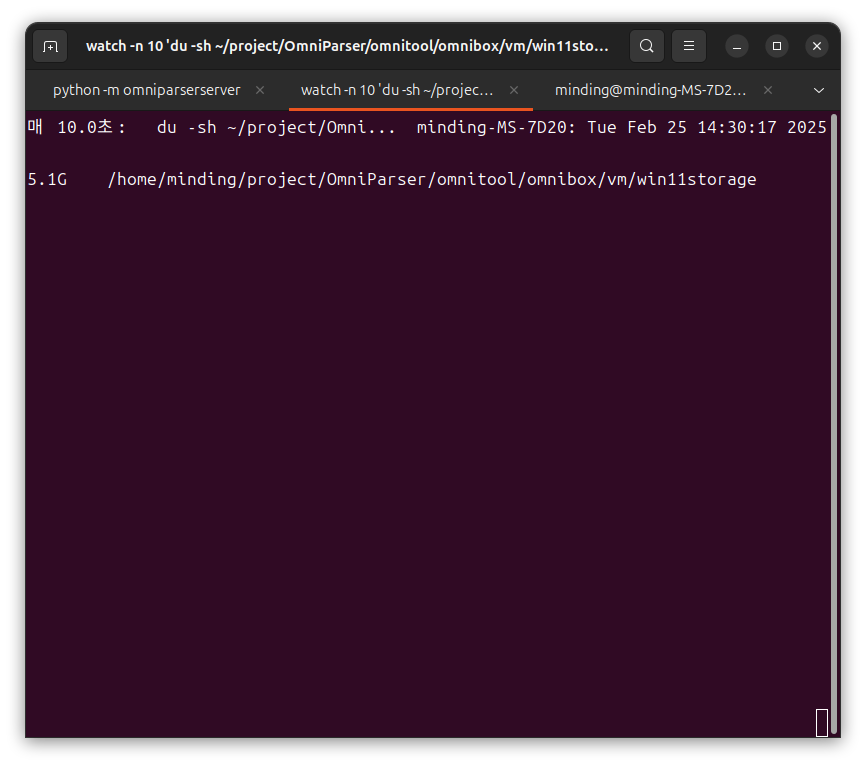
용량이 5.1G로 변하며 설치가 진행중인 모습을 확인할 수 있었다. 혹시나 권한 문제로 설치가 중단될 수도 있으니, 해당 문제가 있는 사람은 sudo를 붙여서 실행해보는 것도 방법일 것이다.
설치가 완료되면 'VM + server is up and running!!'이라는 메시지가 터미널 창에 노출될 것이다. 최초 설치 이후에는 아래 명령어를 통해 컨테이너를 빌드하고 멈출 수 있다.
./manage_vm.sh start
./manage_vm.sh stop
# 삭제가 필요할 시
./manage_vm.sh delete
3. gradio
gradio는 omnibox에서 명령을 제공하고 추론과 실행을 감시하는 UI의 역할이다. 기본적으로 위에서 설정한 omni 가상환경을 필요로한다.
# gradio 폴더로 이동
cd OmniParser/omnitool/gradio
# omni 가상환경 실행중인지 확인
conda activate omni
# gradio 서버 실행
python app.py --windows_host_url localhost:8006 --omniparser_server_url localhost:8000
OmniTool을 이용해 LLM 모델과 함께 사용해보기
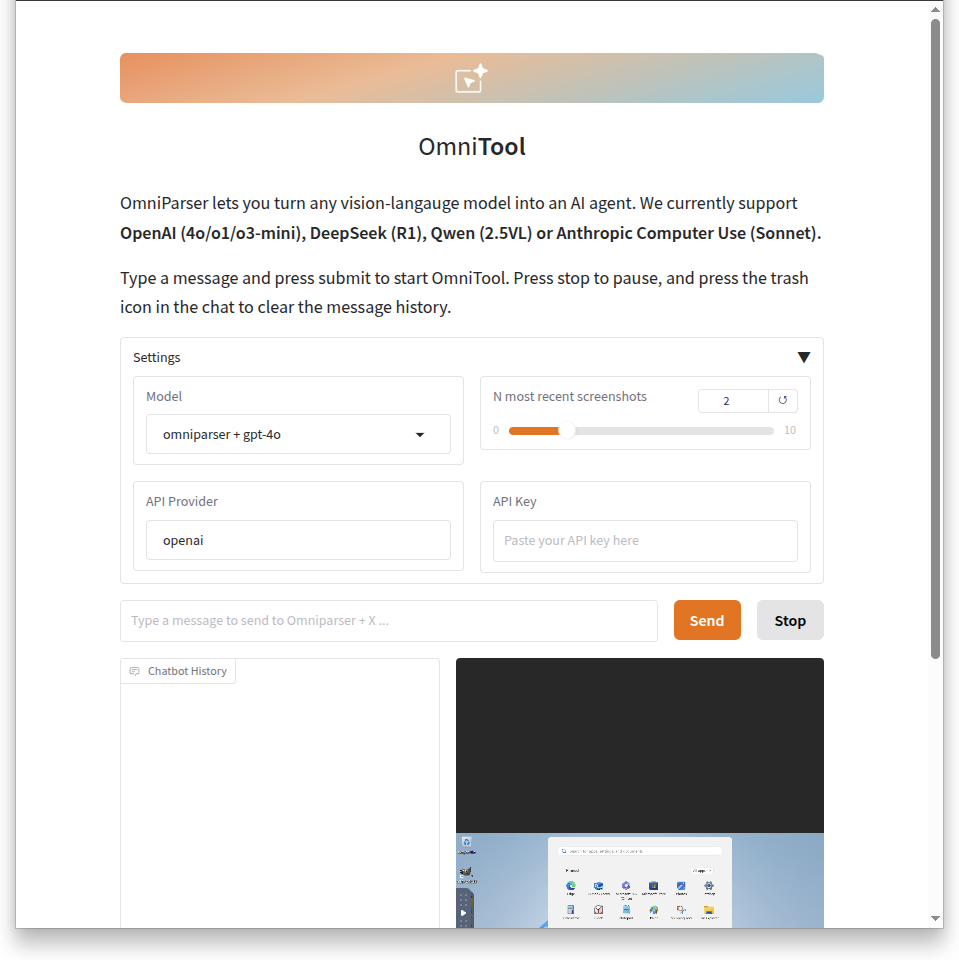
위 세팅이 모두 마무리 된 다음, gradio의 WebUI(http://0.0.0.0:7888/)에 접속하면 위와 같은 화면이 노출된다. Settings에서 사용할 LLM Model을 선택할 수 있다. 기본적으로는 API Key(유료버전)를 입력해야 사용할 수 있다. 만약 과금이 부담된다면, 이 영상을 한번 참고하길 바란다.
나는 OpenAI의 API KEY를 이용했다. 브라우저를 열고 닫는 간단한 작업을 수행해봤다.
LLM에게 명령을 내렸을 때, 구조화된 데이터를 읽고 그에 따른 수행 과정 자체는 잘 판단했으나, 실제 VM에서의 행동은 제대로 이루어지지 않는 모습이었다. 생각보다는 실망이었다..!
명령에 따른 LLM에서 답변은 아래와 같다. 위치와 행동은 제대로 파악했으나, 이상하게도 작동은 하지 않았다.
Analysis: The task is to quit the browser, and the screen currently shows the Google Chrome interface with an ad privacy overlay. To close the browser, I need to click the 'X' button at the top-right corner of the window.
Next Action: left_click
Box ID: 49
box_centroid_coordinate: [1029, 29]
Next I will perform the following action: {'action': 'mouse_move', 'coordinate': [1029, 29]}
Moved mouse to (1029, 29)
Next I will perform the following action: {'action': 'left_click'}
Performed left_click
조금 더 비싼 모델을 사용해야했을까..? 기본 모델이다보니 사용량이 한계인 점도 있는 것 같다. 다음에 사용할 때는 이런 점들을 보완할 수 있는 방법을 찾아봐야 할 것 같다.
'Minding's Programming > Knowledge' 카테고리의 다른 글
| [QA] Positive / Negative / Edge Case 개념 정리 (0) | 2025.03.24 |
|---|---|
| [Testing] SW 테스트 기본 개념들 정리 (0) | 2025.03.04 |
| [Python 3.13] Python에서 GIL을 비활성화 할 수 있다? (0) | 2025.02.24 |
| [QA/Testing] 모바일 앱 테스트 자동화 오픈소스 Appium 사용해보기 (0) | 2025.02.20 |
| [프로젝트] Catch Me My Capital - 합리적인 투자 의사결정을 위한 금융 데이터 파이프라인 및 백테스팅 도구 (테스트 도입 편) (0) | 2025.02.18 |