Github: https://github.com/DE-ta-e-il/catch-me-my-capital
GitHub - DE-ta-e-il/catch-me-my-capital: A data engineering project focused on collecting and managing financial data with a vis
A data engineering project focused on collecting and managing financial data with a vision for backtesting and analysis. - DE-ta-e-il/catch-me-my-capital
github.com
프로젝트 개요
프로젝트 배경
"우리는 정말 원숭이보다 투자를 더 잘하고 있을까요?"라는 질문에 대부분의 사람은 이 질문에 자신있게 대답하지 못한다. 그 이유는 투자 세계는 종종 객관적인 데이터보다 감정과 편향된 사고에 의해 좌우되며, 두려움, 탐욕, 확증 편향 등 심리적 요인들이 투자 판단에 큰 영향을 미친다. 그리고 이는 종종 비합리적인 결정을 초래하기 때문이다.
이러한 문제를 극복하기 위해서는 데이터 기반의 분석과 전략적 판단이 필수적이다. 본 프로젝트는 사용자들이 이러한 심리적 함정을 벗어나 객관적인 데이터를 바탕으로 투자 결정을 내릴 수 있도록 돕는 도구를 제안한다. 이를 통해 감정에 흔들리지 않는 합리적이고 체계적인 투자 문화를 정착시키고자 한다.
목표
- 금융 데이터의 통합 및 시각화를 통한 포트폴리오 관리 최적화
- 데이터의 체계적인 처리 및 분석을 위한 ETL 파이프라인 구축
- 확장 가능한 AWS기반 솔루션 설계
- Serverless AWS 서비스와 버킷, DW 클러스터 활용
- 자동화된 워크플로우
- 주식, 채권, ETF, 외환 등 다양한 투자 상품을 필터링하여 인사이트 생성
- Tableau 기반 인터랙티브 대시보드
- 맞춤형 필터 및 뷰 제공
- 데이터 처리
- 데이터 수집, 변환, 정제 및 분석 제공
- 데이터 품질 관리: 누락 데이터 처리 및 중복 제거
- 최적화된 데이터셋 제공을 통한 빠른 인사이트 도출
- 소프트 스킬 배양
- 제한된 일정 안에서 우선순위를 정하고, 목표를 체계적으로 달성
- Scrum과 Sprint를 효과적으로 관리하여 지속적인 개선 실현
기술 스택
- 데이터 수집 및 처리: Python(3.11), AWS Glue, dbt
- Python 패키지 의존성
- 백테스팅 구현 관련: backtrader, quantstats
- 데이터 수집 관련: cloudscraper, requests,bs4, yfinance
- Python 패키지 의존성
- 데이터 저장: AWS S3, AWS Redshift, AWS RDS
- 데이터 서빙 및 시각화: Tableau(BI), Lambda(API)
- 오케스트레이션: AWS MWAA(Airflow 2.10.1)
- 운영 자동화: Terraform(인프라 설정), GitHub Actions(CI/CD), AWS CloudWatch(모니터링)
- 보안: AWS Secrets Manager, AWS VPC
- 협업 관리: Jira, Postman, GitHub, Slack, Discord
- 로컬 개발 환경 구성: Docker + Airflow(2.10.1)
프로젝트 설계 및 아키텍처

설계 의도
1. 두 개의 계정으로 아키텍처를 구현함.
본 프로젝트는 프로그래머스 데이터 엔지니어링 데브코스 4기의 최종 프로젝트로 진행했다는 점을 먼저 알린다. 주최 측에서 제공하는 AWS 계정이 있었지만, 해당 계정으로 이용 가능한 서비스 자원이 한정되어 있었다. 따라서 별도의 팀 계정을 따로 생성하여 2개의 계정을 연결해 사용하는 방식을 채택했다. 2개의 계정은 각각 아래와 같은 역할을 가지고 있다.
- A 계정 (팀 계정 - MWAA 전용 AWS IAM)
- MWAA (Managed Workflows for Apache Airflow): AWS에서 제공하는 Airflow 완전 관리형 서비스로, 설치/유지보수/업그레이드 및 확장을 자동으로 처리한다. 관리가 용이한 점과 단기간에 개발을 할 수 있다는 장점이 있어 채택.
- 실제 기업 사례에서도 Airflow 초기 도입에 MWAA를 많이 사용한다는 블로그 글 등 참고 (ex. 29CM 개인화 추천시스템 사례)
- 데이터 수집과 파이프라인 관리에 사용되는 DAG 실행하는 환경

- B 계정 (데브코스 지원 계정 - Glue, DB 전용 IAM / 아래 서비스는 모두 지원되는 항목)
- S3: 데이터 레이크로 사용할 목적으로 구성함. 여러 형태의 데이터를 원본 형태로 수용할 수 있으며, 용량 제한 및 연결 편의성 측면에서 뛰어나다는 점이 있어 채택.
- Glue: 서버리스 기반의 데이터 처리 서비스로, 간단한 작동 방식으로 Spark를 통해 데이터를 처리할 수 있으며 데이터 처리 과정을 간소화할 수 있다는 장점이 있어 채택.
- Redshfit: 데이터 웨어하우스로 사용. 데이터 수요에 따라 자원이 유연하게 확장되며, 컬럼형 방식 및 병렬 처리가 가능해 빅 데이터셋에 효율적인 장점이 있기 때문에 채택.
- Lambda: API 서버를 구성하는 데 사용. 트래픽에 따라 자동 확장 가능한 서버리스 관리형 서비스이며, 사용하지 않을 시 비용이 따로 발생하지 않음. API 사용량과 API로 제공하는 데이터 크기를 고려했을 때 Lambda로 구성하는 게 효율적이라 판단되어 채택.
- RDS: API 서빙용 데이터베이스로 사용. ElasticCache를 in-memory 캐시로 사용하는 관리형 서비스다. Redshift에 저장되어 있는 데이터를 RDS에도 저장하여 API 서빙 시 빠른 반응을 할 수 있도록 하기 위해 채택.
- Secrets Manager: API KEY 등 비밀 정보를 Secrets Manager를 통해 안전하게 보관 및 사용.
- 계정 간 연동 방법
- 팀 계정(MWAA service role)과 데브코스 계정(Glue role)에 각각 IAM Role 구성
- 데브코스 계정에 Trusted entity 설정
- Glue / Redshift / S3 등과 상호작용을 위한 정책 권한 설정
- Secrets Manager 권한 설정
2. 데이터 파이프라인 아키텍처를 메달리온 아키텍처로 설정
메달리온 아키텍처는 데이터 파이프라인을 Bronze, Silver, Gold 세 계층으로 구성하는 아키텍처로, Bronze에 원본 데이터를 저장한 뒤 계층이 올라갈 때마다 데이터를 점진적으로 개선하는 방식을 가지고 있다. 메달리온 아키텍처를 채택한 이유는 아래와 같다.
- 3개의 계층으로 데이터를 점진적으로 개선할 수 있어 고품질의 데이터를 제공할 수 있다.
- 데이터 리니지 추적이 쉬워(모든 데이터가 B -> S -> G의 흐름을 가지기 때문) 체계적인 데이터 관리가 가능하다.
- 데이터가 변환되는 과정을 각 레이어 별로 정의할 수 있다.
본 프로젝트에서는 각 레이어 별로 다음과 같은 변환과정을 거쳤다.
Bronze(S3 / 원본 데이터) -> Silver(Redshift / 정제 및 변환된 데이터) -> Gold(Redshift&RDS / 시각화 및 데이터 서빙에 적합한 형태의 데이터)
데이터 파이프라인이 작동하는 흐름은 아래의 순서대로 진행되도록 설계했다.
- MWAA DAG에서 API 호출 및 웹 크롤링 작업을 통해 Raw Data를 수집
- 수집된 Raw Data를 B 계정(데브코스 계정)의 S3에 저장 (Bronze Layer)
- Silver Layer를 위한 DAG 실행, 데이터 스키마 변경 여부를 감지하기 위해 Glue 크롤러 트리거
- Glue 크롤러가 Data Catalog를 업데이트
- Silver Layer DAG에서 Glue ETL job을 실행 (Spark)
- Glue ETL job이 완료된 데이터를 Redshift에 저장해 분석 준비 (Silver Layer)
- Gold Layer를 위한 DAG 실행, 이 작업에서는 DBT(Data Build Tool)를 사용하며, 결과 데이터를 Redshift에 저장
- Gold Layer 데이터는 분석 및 시각화 관련 데이터를 프로덕션에서 쉽게 사용할 수 있도록 RDS에도 저장
- Gold Layer 데이터를 AWS Lambda에 구성한 FastAPI 서버를 통해 데이터 서빙
- Tableau와 연동되어 데이터 시각화를 제공
- Athena를 통해 테스트 쿼리 실행
- DAG, Glue job script의 변경 사항이 발견될 때마다(main 브랜치에 변동 사항이 있을 경우) Github Actions을 통해 S3에 자동 배포함.
3. Terraform을 활용해 프로비저닝
계정을 2개 사용하는 이유 중 하나였던 MWAA는 AWS의 다른 서비스에 비해 요금이 높은 서비스다. 팀 사정상 MWAA를 프로젝트 기간동안 띄워둘 수는 없었기 때문에, DAG을 실행하는 동안에만 MWAA를 실행할 수 있도록 하는 프로비저닝 도구가 필요했다. 팀원과 논의 후에 Terraform을 프로비저닝 도구로 사용하기로 결정했다.
[Terraform 세부 설정]
Terraform으로 프로비저닝하는 서비스들은 아래와 같다.
- 서브넷:
- MWAA는 3개의 서브넷으로 구성되어 있으며, 각 서브넷은 3개의 가용 영역에 분산.
- Webserver 서브넷: Airflow 웹서버가 위치.
- Worker 서브넷: Airflow 작업자(Worker)가 실행.
- Scheduler 서브넷: Airflow 스케줄러가 실행.
- **인터넷 게이트웨이(IGW)**는 Webserver 서브넷에 연결되어, 웹서버가 외부와 통신할 수 있도록 설정.
- NAT 게이트웨이는 Worker와 Scheduler 서브넷에 배치되어, 외부 인터넷 액세스가 필요할 경우를 지원.
- MWAA는 3개의 서브넷으로 구성되어 있으며, 각 서브넷은 3개의 가용 영역에 분산.
- 클러스터:
- Airflow 작업은 AWS Fargate 클러스터에서 실행.
- 서버리스 기반으로 확장성과 관리 효율성 극대화 및 개발 시간 단축.
- 메타데이터 DB:
- Airflow 메타데이터 데이터베이스는 Aurora 인스턴스.
- 이 데이터베이스는 Webserver 서브넷에 위치.
- CloudWatch:
- SQS:
- Airflow의 브로커로 사용되어 태스크 메시지를 관리.
- MWAA 로그 및 성능 모니터링 도구로 사용.
- Webserver, Worker, Scheduler의 실행 상태를 추적 가능.
- SQS:
- Secrets Manager:
- Airflow 변수 및 연결 정보를 안전하게 저장.
- 민감한 데이터(예: API 키, 데이터베이스 자격 증명 등)의 보호를 위해 사용.
- S3:
- Airflow의 루트 폴더로 사용.
- DAG 파일, 플러그인, 환경 파일이 저장됨.
- IAM 역할 및 정책:
- MWAA가 필요한 권한을 가질 수 있도록 IAM 역할 및 정책 구성.
- S3, SQS, CloudWatch, Secrets Manager 등과 통합을 지원.
[Terraform 프로젝트 구조]

[Terraform 실행 절차]
- Secrets 초기화:
- Secretsmanager에서 시크릿을 바로 삭제하지 않기 때문에 Terraform 실행 전에 Startprocedure.sh를 실행하여, 기존에 저장된 환경 변수를 정리.
- Terraform Apply:
- terraform plan/apply 명령어를 실행하여 MWAA 환경을 프로비저닝.
- 실행 결과로 위의 리소스가 배포됨.
데이터 파이프라인 프로세스
위에서 설명한 메달리온 아키텍처를 기본으로 데이터 파이프라인을 구성했으며, 데이터 소스 수집 계층인 Ingestion과 프로덕션 계층인 Serving Layer를 양 끝에 붙인 형태로 최종 구성했다.
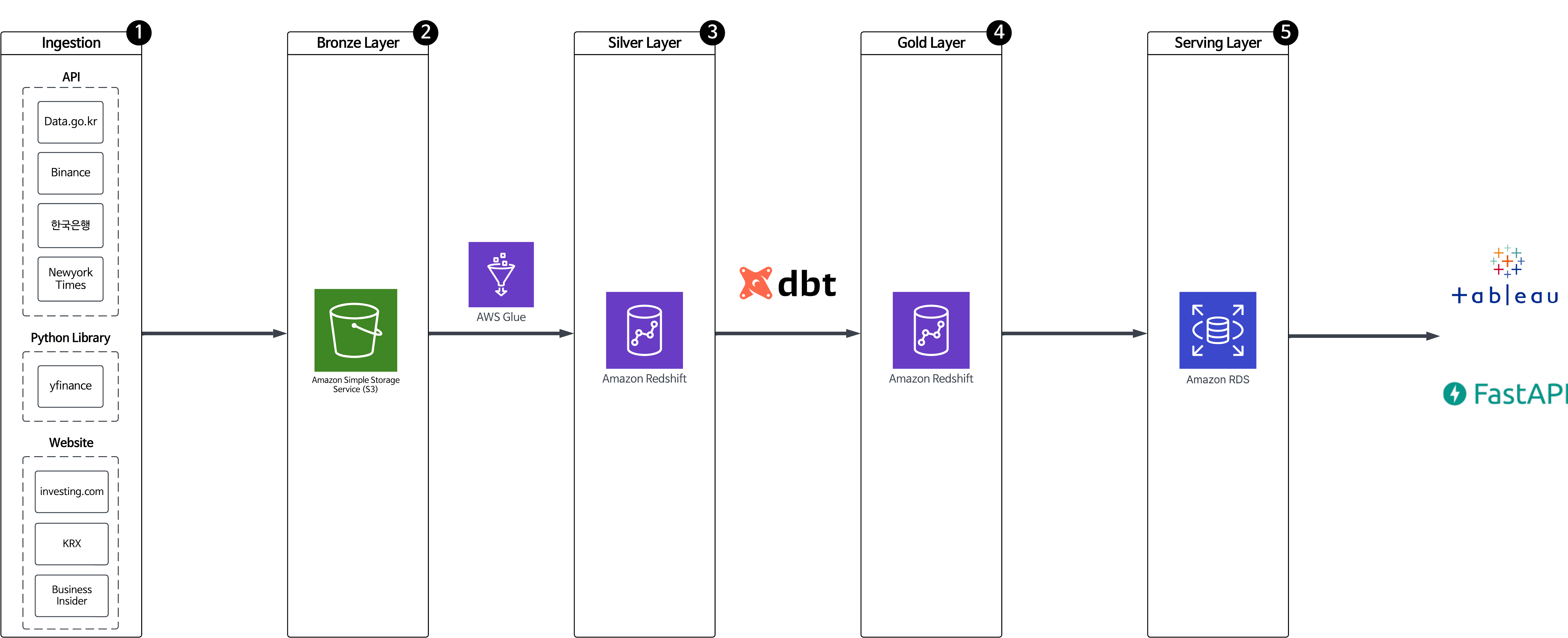
1. Ingestion(데이터 소스)
프로젝트 주제가 '합리적인 투자 의사결정을 위한 금융 데이터 파이프라인 및 백테스팅 도구'인 만큼, 여러 금융 데이터 소스가 필요했다. 금융 데이터를 구할 수 있는 소스에 대한 조사를 마친 뒤 아래 기준에 따라 선정했다.
- 일일 API 제한량이 프로젝트에 사용할 수 있을만큼 충분한지
- 데이터에 대한 신뢰성이 보장되는지
- 요금이 부과되지 않는 소스인지
- 특정 주기 별 배치 데이터를 수집할 수 있는 데이터인지 (Daily, Monthly, Quarterly, Yearly)
그 결과 RESTful API, 웹 크롤링, Python 라이브러리 등의 방법을 통해 아래와 같은 데이터들을 수집할 수 있었다.
- API 호출: Binance API(코인), NewYorkTimes API(뉴스), 한국은행 API(경제지표) 등
- 웹 크롤링: Investing.com(주식, 종합지수), KRX(한국 ETF), Business Insider(채권, MSCI 지표) 등
- Python 라이브러리: yfinance(환율, 주식 등)
2. Bronze Layer
위에서 설명한 것처럼, 본 프로젝트는 메달리온 아키텍처로 구성했다. 제일 첫 번째 순서인 Bronze Layer에는 원본 데이터를 저장하는 계층(Glue ETL job 사용을 고려해 데이터 구조를 일부 변경하는 데이터도 있긴했다.)으로, 데이터 레이크로 사용할 수 있는 S3에 데이터를 저장했다.
데이터는 Airflow DAG을 통해 각 데이터 성격에 따라 특정 주기 별로 API 호출, 웹 크롤링 등의 방법을 통해 수집했다.

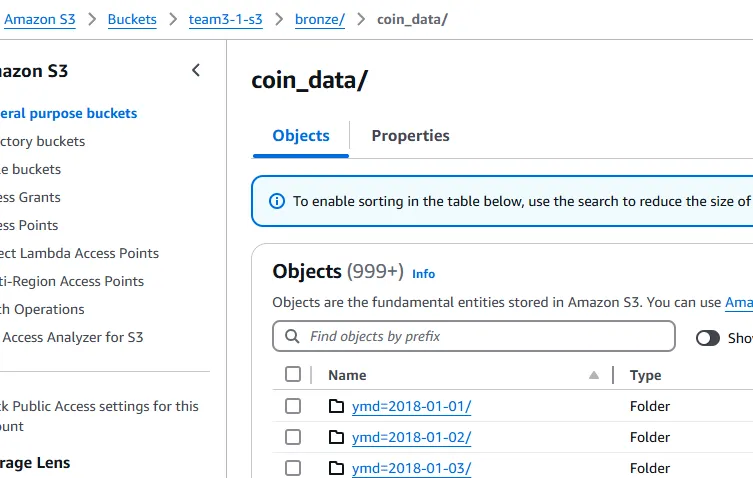
이렇게 수집된 데이터는 각 데이터 폴더에 묶여 S3에 날짜 기준의 파티셔닝 키를 사용해 저장했다. AWS Glue Crawler의 자동으로 파티셔닝 키를 인식하는 기능을 이용해 추후 날짜 인덱스로 활용해 효율성을 높이기 위함이었다. (AWS Glue에서의 파티션 활용 관련 링크)
아래 이미지와 같이 파티셔닝 키를 설정하면, 크롤러가 데이터를 읽은 뒤 Data Catalog에 저장할 때 ymd라는 파티션 인덱스를 자동으로 생성해준다. ('date'라는 파티셔닝 키를 사용하지 않은 이유는, 데이터 원본에 date라는 칼럼이 있는 경우가 많기 때문에 칼럼 명 중복 방지를 위해 'ymd'라는 키를 사용했다.)
3. Silver Layer
Silver Layer에는 원본 데이터를 분석하기 적합한 형태로 정제하고 변환한 데이터를 저장하는 계층이다.
Silver Layer DAG을 Airflow를 통해 실행하면, 우선 AWS Glue Crawler를 통해 Bronze Layer의 데이터를 Data Catalog의 테이블 형태로 저장한다. 이후 Glue ETL job에서 GlueContext의 from_catalog 또는 from_options 메서드를 이용해 S3에 저장된 데이터를 수집해 Glue의 Spark Engine을 통해 적절히 변환한다.
이렇게 정제 및 변환된 데이터를 구조화하여 Redshift에 저장한다. 저장 시 테이블의 사용 목적에 따라 fact, dimension 테이블로 나누어 저장한다. 각 테이블의 정의는 아래와 같다.
- fact 테이블: 실제 사실이 기록된 테이블(ex. 주가의 일봉 종가 데이터 등)
- dimension 테이블: fact 테이블에서 참고하는 메타 데이터 성격의 테이블
- fact_, dim_ 과 같은 prefix를 붙여 테이블 이름 지정
4. Gold Layer
Gold Layer에는 시각화와 데이터 서빙에 적합한 형태로 저장되는 계층이다.
시각화 또는 데이터 서빙에 필요한 데이터 형태가 정해지면, Redshift에 테이블 형태로 저장된 Silver Layer 데이터를 추출한다. 이 과정에서는 dbt(Data Build Tool)를 이용해 SQL Query로 데이터를 변환하는 방식을 사용했다. 변환된 데이터는 다시 Redshift의 Gold 스키마에 저장되며, 테이블 이름 앞에 'mart_'라는 prefix를 붙여 저장했다.
5. Serving Layer
실제 이용자들이 데이터를 확인할 수 있는 Serving Layer에서는 크게 2가지 기능을 제공했다.
1. Tableau를 사용한 시각화(대시보드 필터링 및 데이터 조작 가능)

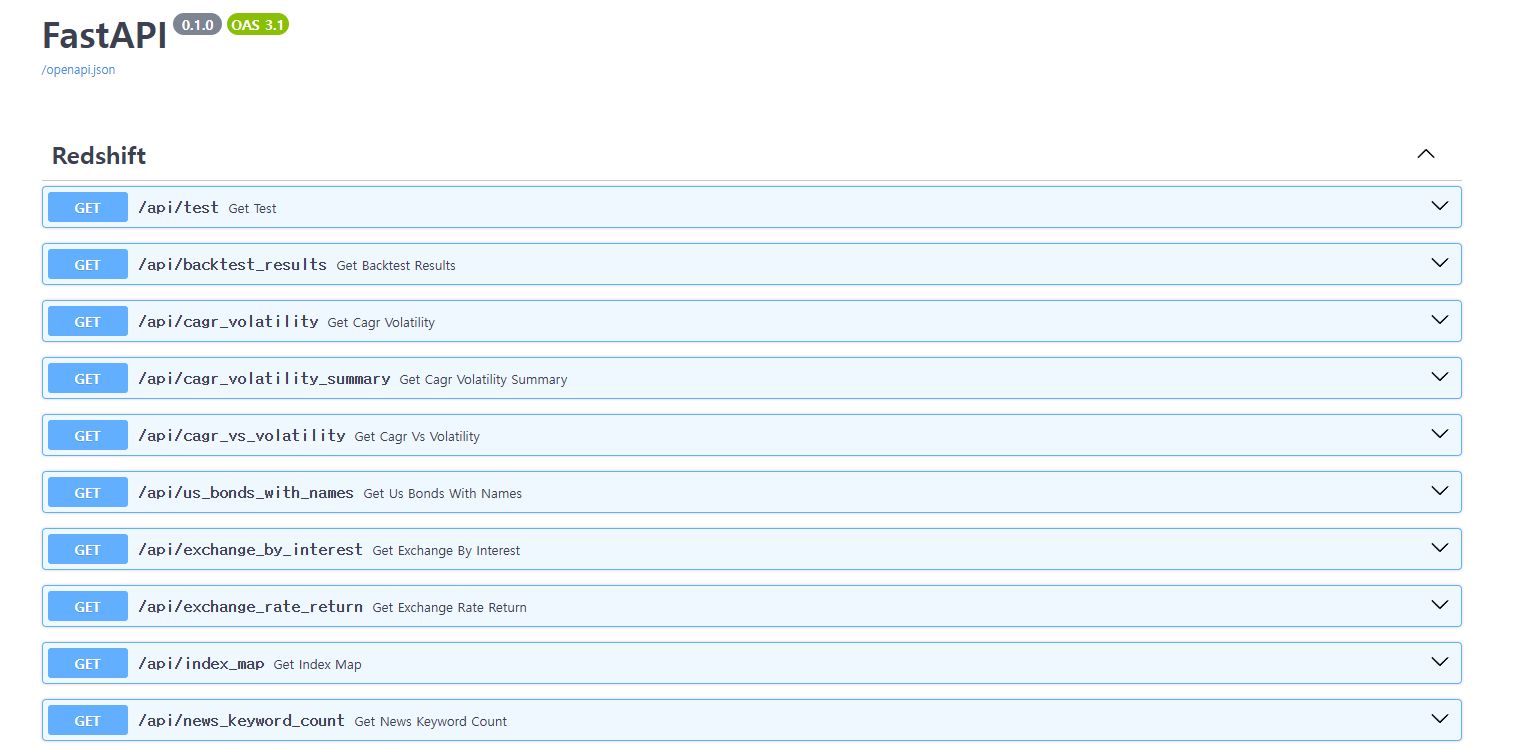
2. AWS Lambda를 사용해 FastAPI 서버로 데이터 호출
FastAPI 서버를 통해 제공되는 데이터는 RDS에 따로 저장하여 대기 시간을 최소화했다.

도전 과제(어려웠던 점)
과거 데이터 수집 문제
- 문제: 10년치 데이터를 수집을 목표로 잡았으나, API 일일 호출량 제한으로 인해 과거 데이터를 수집하는 데 어려움을 겪었다.
- 해결: Airflow DAG의 Backfill을 이용한다면 일일 호출량 제한에 걸릴 확률이 매우 높았기 때문에, 1회 호출 시 과거 데이터 기간을 길게 잡아 한꺼번에 수집한 후, 파티셔닝 키를 기준으로 다시 나누어 S3에 저장하는 방식을 채택했다.
부적합한 데이터 읽기 방식 선택으로 AWS Glue 실행 시간 지연
- 문제: AWS Glue Crawler가 데이터를 읽을 때 의도치 않게 과도하게 많은 파티션으로 분할하는 경우가 발생했고, 따라서 각 파티션을 처리하는데 많은 시간이 소요되는 문제가 발생했다.
- 해결: AWS Glue 공식 문서를 참고해 파티션 처리 방식을 재검토했고, 데이터 읽기에 최적화된 메서드로 변경하여 성능을 개선했다.
데이터 일관성 문제
- 문제: 다양한 소스에서 수집하는 데이터 사이의 데이터 형식(날짜 등)이 불일치해 통합 등의 문제가 발생했다.
- 해결: 데이터 표준화 규칙을 설정하고, 이에 맞추어 데이터 형식을 검사하는 로직을 DAG에 추가했다.
데이터 소스 문제
- 문제: 주식, 코인 등의 데이터는 종류가 매우 많아 선정하기 어려웠고, 채권/ETF 등의 데이터는 수집하기 어렵거나 제한된 날짜의 데이터만 가지고 있는 경우가 있어 수집 문제가 발생했다.
- 해결: 'API 호출 + 웹 크롤링' 등 다양한 방법을 결합해 사용한 뒤 데이터를 표준화해 저장하는 방식을 채택했다.
팀원 간 개발 환경 통일 문제
- 문제: 팀원 간 작업 환경(Mac 2명, Linux 1명, Windows(WSL) 1명) 및 코드 린팅&포맷팅 도구가 서로 달라 코드 및 개행 표현(LF/CRLF)이 다른 문제가 발생
- 해결: 코드 린터 및 포맷터 도구로 Ruff를 사용하고, 개행 표현의 경우 Windows 환경에서 .gitattributes 파일을 통해 Git에 push할 경우 개행 표현 방식을 LF로 고정하도록 설정
- Ruff: black, flake8, isort의 기능을 통합한 도구로, Rust로 구현되어 속도가 빠르다. 최근 Airflow, Pandas, FastAPI 등 대중적인 라이브러리에서 사용하며 Github Star의 성장세가 가파르게 상승하는 주목받는 도구.
인프라/클라우드 구성 퀄리티 향상에 대한 과금 문제
- 문제: 데브코스에서 지원 받는 항목이 아닌 경우 팀원들이 사비를 들여 서비스 과금을 부담해야 하는 상황이기 때문에, 인프라 및 클라우드 구성 퀄리티 향상과 과금 부담 간의 딜레마가 발생
- 해결: 퀄리티 향상과 더불어 과금을 최소화 하기 위해 프로젝트를 단계적으로 Develop하는 방식을 선택
- 1단계: MWAA를 사용해 개발 기간을 단축, 이외에는 데브코스에서 지원되는 서비스 항목을 최대한 활용(Glue, Redshift, S3 등) - 테라폼으로 프로비저닝하여 DAG을 실행시키는 시간 동안에만 MWAA 실행
- 2단계: Glue 대신 EMR을 사용해 Spark로 데이터 변환하는 과정을 처리
- 3단계: EKS를 사용해 Airflow, Spark Engine 등을 구성하고, 컨테이너를 관리
DAG 작성 방식 통일 문제
- 문제: Airflow DAG 코드 작성 시 팀원 간 PythonOperator 사용과 Taskflow API 사용 방식 간 통일이 되지 않는 문제
- 해결: Taskflow API 방식을 사용할 경우 XCom 데이터가 json 직렬화 가능한 값으로만 제한되며, 의존성 충돌 문제, 디버깅 및 유지보수, 성능 문제 등이 발생할 수 있어 PythonOperator를 사용하는 방식으로 통일
- Taskflow가 무조건 나쁘다는 뜻은 아님! Pythonic한 코드를 작성할 수 있으며, 간단한 ETL 프로세스에서는 오히려 강점이 있음. 대신 PythonOperator가 커스텀 및 디버깅에 유리한 점이 있다는 것!
결과 및 성과
성과 요약 (프로젝트 및 개인 관점)
- 사용자들에게 유용한 인사이트 제공
- 다양한 금융 데이터 기반의 분석 및 투자 도구를 제공
- 과거부터 현재까지의 데이터를 1일 단위로 제공해 잠재적 리스크 및 안정적인 포트폴리오 구성 가능
- 여러가지 포트폴리오에 대한 백테스팅 도구를 제안해 안정적이면서 이익을 극대화한 포트폴리오 구성에 도움
- 기술적 역량 향상
- 확장 가능한 파이프라인을 구축해볼 수 있는 경험이 됨
- 단기간에 새로운 기술들을 익혀 프로젝트에 적용
- 매니지드 서비스들의 가격 대비 성능에 대한 감각
제한점 및 향후 계획
- 데이터 소스 추가, automation 고도화
- 스트리밍 데이터 처리
- 머신러닝 모델 적용을 통한 포트폴리오 분석 고도화
- 인프라 고도화 (MWAA + Glue → EMR on EKS 등)
- 데이터 품질 테스트 추가
- 웹/앱서비스로의 확장
NEXT STEP
다음 글에는 아래 내용들을 적용해 프로젝트의 퀄리티를 향상시킨 결과를 소개하고자 한다.
- 비동기 처리 - 다양한 작업이 한 번에 실행할 수 있는 코드에 비동기를 적용하여 작업 시간을 줄임
- 테스트 도구 추가(Unittest) - 데이터 수집 및 품질에 대한 테스트 도구를 추가해 신뢰성 향상
- 웹 UI 추가 - 웹서비스로의 확장을 위한 UI를 추가
'Minding's Programming > Knowledge' 카테고리의 다른 글
| [Postman/Github Actions] Github Actions를 통해 API 테스트 자동화하기 (0) | 2025.02.13 |
|---|---|
| [QA/Testing] Charles Proxy Tool - 테스트 효율을 높일 수 있는 툴 (0) | 2025.02.07 |
| [Kafka/Python] Kafka 설치 방법(Conduktor) (1) | 2024.12.05 |
| [Python/Unittest] Unittest (0) | 2024.12.02 |
| [Docker] Docker Volume (0) | 2024.11.15 |