728x90
반응형
Tensorflow 공식 홈페이지에 있는 Tensorflow Tutorial로 TF와 Keras의 기본 지식을 배워보자!
https://www.tensorflow.org/tutorials/keras/classification?hl=ko
첫 번째 신경망 훈련하기: 기초적인 분류 문제 | TensorFlow Core
Note: 이 문서는 텐서플로 커뮤니티에서 번역했습니다. 커뮤니티 번역 활동의 특성상 정확한 번역과 최신 내용을 반영하기 위해 노력함에도 불구하고 공식 영문 문서의 내용과 일치하지 않을 수
www.tensorflow.org
첫번째 신경망 훈련하기 : 기초적인 분류 문제
# tensorflow, keras import
import tensorflow as tf
from tensorflow import keras
import numpy as np
import matplotlib.pyplot as plt
print(tf.__version__)
>>> 2.4.1패션 MNIST 데이터셋 임포트
- 10개의 범주, 7만개의 이미지
- 해상도 28*28 픽셀

- 훈련 데이터셋 6만개 이미지
- 테스트 데이터셋 1만개 이미지
# 데이터셋 임포트
fashion_mnist = keras.datasets.fashion_mnist
(train_images, train_labels), (test_images, test_labels) = fashion_mnist.load_data()- 이미지는 28*28 크기의 넘파이배열
- 픽셀 값은 0과 255 사이
- 레이블은 0에서 9까지의 정수배열 (= 이미지(옷)의 클래스)

- 각 이미지는 하나의 레이블에 매핑
- 데이터셋에는 클래스 이름X --> 나중에 이미지 출력시 사용위해 별도의 변수 사용
데이터 탐색
print('훈련 데이터셋의 shape: ', train_images.shape)
print('훈련 데이터셋의 labels: ', len(train_labels))
print('레이블: ', train_labels)
print('테스트 데이터셋 shape: ', test_images.shape)
print('테스트 데이터셋의 labels: ', len(test_labels))
>>>
훈련 데이터셋의 shape: (60000, 28, 28)
훈련 데이터셋의 labels: 60000
레이블: [9 0 0 ... 3 0 5]
테스트 데이터셋 shape: (10000, 28, 28)
테스트 데이터셋의 labels: 10000데이터 전처리
- 픽셀값의 범위 0 ~ 255 사이 --> 0 ~ 1 사이로 조정
- 딥러닝 모델은 단순한 정수보다 0 ~ 1 사이 실수 처리할 시 더 좋은 성능 (정규화)
- 이미지에 255를 나눠줌
plt.figure()
plt.imshow(train_images[0])
plt.colorbar()
plt.grid(False)
plt.show()
train_images = train_images / 255.0
test_images = test_images / 255.0- 훈련세트에서 25개의 이미지와 클래스 이름 출력
- 데이터 포맷이 올바른 지 확인
plt.figure(figsize=(10,10))
for i in range(25):
plt.subplot(5,5,i+1)
plt.xticks([])
plt.yticks([])
plt.grid(False)
plt.imshow(train_images[i], cmap=plt.cm.binary)
plt.xlabel(class_names[train_labels[i]])
plt.show()
모델 구성
- 신경망 모델의 층을 구성한 다음 모델 컴파일
층 설정
- 신경망의 기본 구성요소 = 층(layer)
model = keras.Sequential([
keras.layers.Flatten(input_shape=(28, 28)),
keras.layers.Dense(128, activation='relu'),
keras.layers.Dense(10, activation='softmax')
])- Flatten 층 : 2차원 배열(28*28)의 이미지 포맷을 28X28 = 784픽셀의 1차원 배열로 변환 (평탄화)
- Dense 층 : 완전연결(fully-connected)층
- 1번째 층 : 128개의 노드, relu 활성화함수
- 2번째 층 : 10개의 노드, softmax 활성화함수 (10개 클래스 중 하나에 속할 확률)
from keras.utils import plot_model
plot_model(model, to_file='model.png')
모델 컴파일
- 모델을 훈련하기 전 필요한 몇 가지 설정 컴파일 단계에서 추가
- 손실 함수
- 옵티마이저
- 지표
model.compile(optimizer='adam',
loss='sparse_categorical_crossentropy', # one-hot encoding 형태로 레이블 제공 시 categorical crossentropy 사용
metrics=['accuracy'])모델 훈련
- 신경망 모델 훈련단계
- 훈련 데이터를 모델에 주입 (train_images, train_labels)
- 모델이 이미지와 레이블 매핑하는 방법 학습
- 테스트 세트에 대한 모델의 예측 (test_images, test_labels)
# 모델 학습 (model.fit 메서드)
history = model.fit(train_images, train_labels, epochs=5)
>>>
Epoch 1/5
1875/1875 [==============================] - 3s 2ms/step - loss: 0.6229 - accuracy: 0.7855
Epoch 2/5
1875/1875 [==============================] - 3s 2ms/step - loss: 0.3850 - accuracy: 0.8634
Epoch 3/5
1875/1875 [==============================] - 3s 2ms/step - loss: 0.3437 - accuracy: 0.8736
Epoch 4/5
1875/1875 [==============================] - 3s 2ms/step - loss: 0.3159 - accuracy: 0.8842
Epoch 5/5
1875/1875 [==============================] - 3s 2ms/step - loss: 0.2979 - accuracy: 0.8904- 훈련 데이터셋에서 89% 정도의 정확도
정확도 평가
test_loss, test_acc = model.evaluate(test_images, test_labels, verbose=2)
print('\n테스트 정확도:', test_acc)
>>>
313/313 - 0s - loss: 0.3553 - accuracy: 0.8682
테스트 정확도: 0.8682000041007996plt.plot(history.history['accuracy'])
# plt.plot(history.history['loss'])
plt.title('Model accuracy')
plt.xlabel('Epoch')
plt.ylabel('Accuracy')
# plt.legend(['Train', 'Test'], loc='upper left')
plt.show()
plt.plot(history.history['loss'])
plt.title('Model accuracy')
plt.xlabel('Epoch')
plt.ylabel('Accuracy')
# plt.legend(['Train', 'Test'], loc='upper left')
plt.show()
- 훈련 세트와 테스트 세트의 정확도 사이 차이는 과대적합 때문
예측 만들기
- 훈련된 모델 사용하여 이미지에 대한 예측 만들 수 있음
predictions = model.predict(test_images)
# 첫번째 인덱스의 예측 확인
predictions[0]
>>>
array([1.6853284e-05, 1.3545680e-08, 2.1632441e-06, 8.6683845e-05,
9.6856570e-07, 3.7058599e-02, 7.8442616e-05, 6.3577071e-02,
3.6513884e-04, 8.9881402e-01], dtype=float32)# 첫 번째 예측 중 가장 높은 신뢰도를 가진 레이블
print(np.argmax(predictions[0]))
# 테스트 레이블과 비교
print(test_labels[0])
>>>
9
9- 10개 클래스에 대한 예측을 그래프로 표현
def plot_image(i, predictions_array, true_label, img):
predictions_array, true_label, img = predictions_array[i], true_label[i], img[i]
plt.grid(False)
plt.xticks([])
plt.yticks([])
plt.imshow(img, cmap=plt.cm.binary)
predicted_label = np.argmax(predictions_array)
if predicted_label == true_label: # 예측이 맞을 경우 파란색, 틀릴경우 빨간색
color = 'blue'
else:
color = 'red'
plt.xlabel("{} {:2.0f}% ({})".format(class_names[predicted_label], # 예측 레이블
100*np.max(predictions_array), # 신뢰도 점수
class_names[true_label]), # 실제 정답
color=color)
def plot_value_array(i, predictions_array, true_label):
predictions_array, true_label = predictions_array[i], true_label[i]
plt.grid(False)
plt.xticks([])
plt.yticks([])
thisplot = plt.bar(range(10), predictions_array, color="#777777")
plt.ylim([0, 1])
predicted_label = np.argmax(predictions_array)
thisplot[predicted_label].set_color('red')
thisplot[true_label].set_color('blue')# 0번째 원소의 이미지, 예측, 신뢰도 점수 배열 확인
i = 0
plt.figure(figsize=(6,3))
plt.subplot(1,2,1)
plot_image(i, predictions, test_labels, test_images)
plt.subplot(1,2,2)
plot_value_array(i, predictions, test_labels)
plt.show()
# 107번째, 예측이 틀림 (엉클부츠인데, 샌들이라고 예측)
i = 107
plt.figure(figsize=(6,3))
plt.subplot(1,2,1)
plot_image(i, predictions, test_labels, test_images)
plt.subplot(1,2,2)
plot_value_array(i, predictions, test_labels)
plt.show()
num_rows = 5
num_cols = 3
num_images = num_rows*num_cols
plt.figure(figsize=(2*2*num_cols, 2*num_rows))
for i in range(num_images):
plt.subplot(num_rows, 2*num_cols, 2*i+1)
plot_image(i, predictions, test_labels, test_images)
plt.subplot(num_rows, 2*num_cols, 2*i+2)
plot_value_array(i, predictions, test_labels)
plt.show()
- 훈련된 모델 사용하여 한 이미지에 대한 예측 만들기
# 테스트 세트에서 이미지 하나를 선택합니다
img = test_images[0]
print(img.shape)
>>>
(28, 28)
- keras는 한 번에 샘플의 묶음 또는 배치로 예측을 만드는 데 최적화
- 하나의 이미지를 사용할 때에도 2차원 배열로 만들어야 함
img = (np.expand_dims(img,0))
print(img.shape)
>>>
(1, 28, 28)# 이미지에 대한 예측
predictions_single = model.predict(img)
print(predictions_single)
>>>
[[1.6853252e-05 1.3545706e-08 2.1632418e-06 8.6683845e-05 9.6856570e-07
3.7058618e-02 7.8442536e-05 6.3577071e-02 3.6513922e-04 8.9881402e-01]]plot_value_array(0, predictions_single, test_labels)
_ = plt.xticks(range(10), class_names, rotation=45)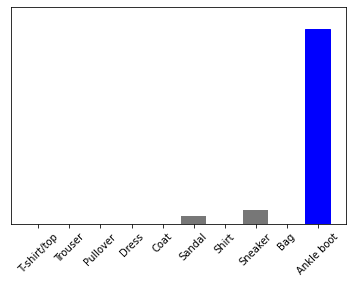
np.argmax(predictions_single[0])
>>>
9728x90
'Minding's Programming > Tensorflow tutorial' 카테고리의 다른 글
| [Tensorflow Tutorial] 자동차 연비 예측하기 : 회귀 (0) | 2021.06.04 |
|---|---|
| [Tensorflow Tutorial] 케라스와 텐서플로 허브를 사용한 영화 리뷰 텍스트 분류하기 (0) | 2021.05.28 |
| [Tensorflow Tutorial] 기본 텍스트 분류 - 영화 리뷰를 사용한 텍스트 분류 (0) | 2021.05.28 |