BeautifulSoup - HTML Parser가 필요한 이유
DOM(Document Object Model)
웹 문서의 구조화된 표현으로, 프로그래밍 언어가 웹 페이지 내의 객체에 접근하고 조작할 수 있게 하는 인터페이스로 동작한다. 주로 자바스크립트에서 웹 페이지의 요소를 선택, 수정, 추가 또는 제거할 때 사용된다.
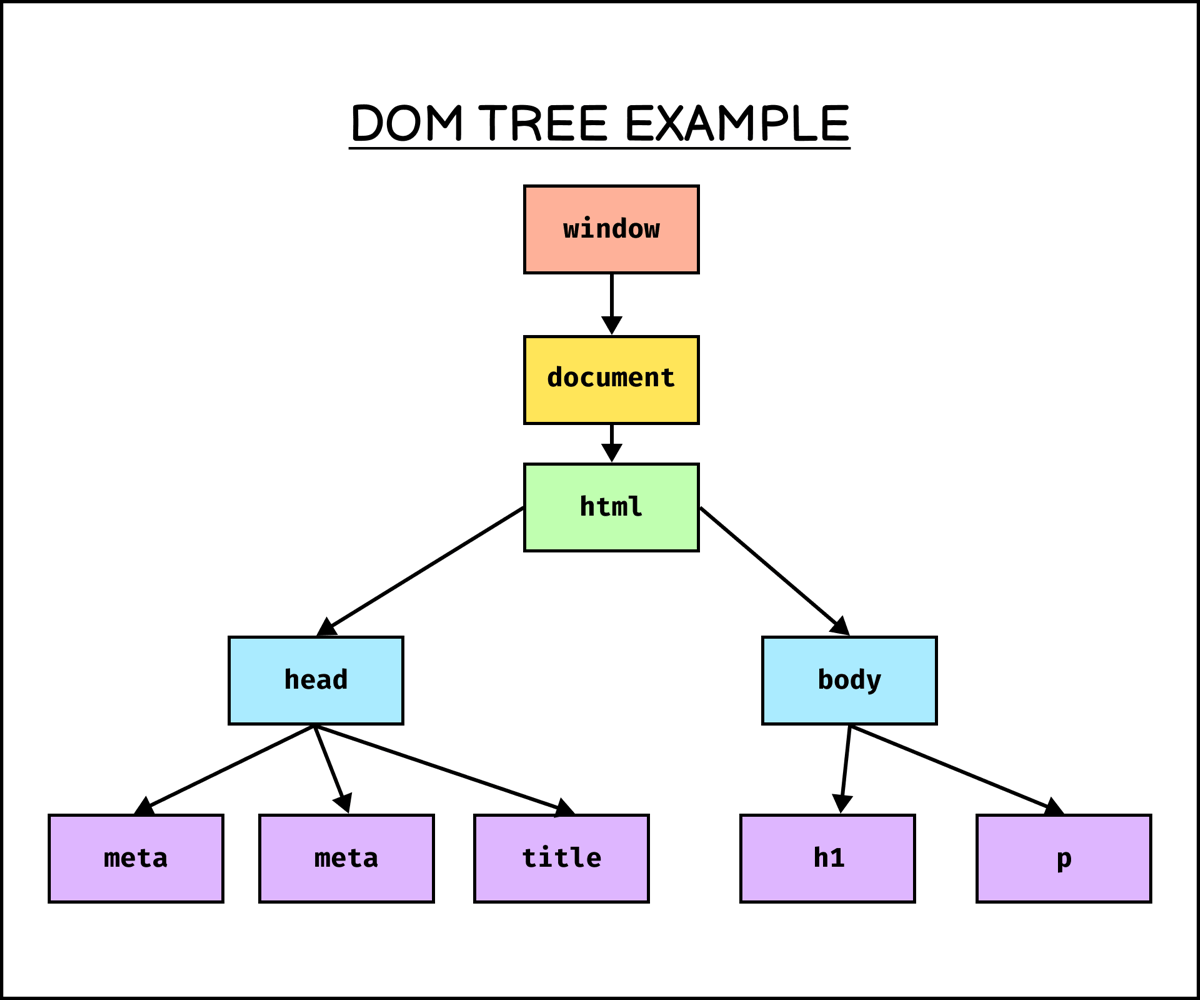
트리 모양처럼 생기기도 한 DOM은 각 노드를 객체 타입으로 여겨 문서 관리를 더욱 편리하게 한다.
웹 브라우저는 DOM을 생성한 후 DOM Tree를 순회해서 특정 원소를 추가/삭제하거나(동적 프로그래밍), 쉽게 찾을 수 있다.
즉, DOM을 이용하면 웹 스크래핑/크롤링도 찾고자 하는 요소를 쉽게 찾을 수 있다. Python으로 HTML 문서를 파싱해서 분석하는 Parser가 있다면, DOM을 만들 수 있을 것이다.
BeautifulSoup을 이용해 HTML 분석하기
Python의 requests 라이브러리를 이용해 웹의 HTTP 통신으로 웹 페이지 정보를 받을 수는 있었지만, 응답 결과에는 긴 텍스트가 반환되어 특정 요소만을 찾기는 힘들다. 이럴 때는 Python의 HTML Parser로 사용할 수 있는 BeautifulSoup을 이용하면 편리하게 요소를 찾을 수 있다.
먼저, BeautifulSoup을 설치해준다.
pip install beautifulsoup4
본격적으로 웹 페이지의 HTML 파일을 Parser를 통해 분석해보자. 우선 requests 라이브러리를 통해 응답을 받아낸다.
import requests
res = requests.get("https://www.example.com")
이제 BeautifulSoup을 통해 응답받은 html 문서 부분을 파싱해보자. (html 문서는 res.text를 뜻한다.)
from bs4 import BeautifulSoup
# bs4는 html 뿐 아니라 xml 등 다른 파일을 파싱할 때도 사용할 수 있다.
# 응답의 html 문서부분(text)을 html 형식으로 파싱한다는 것을 명시
soup = BeautifulSoup(res.text, 'html')
1. .prettify(): html 파일을 보기 편하게 출력하기
# .prettify() 메서드: html 파일을 보기 편한 형태로 출력
print(soup.prettify())
>>>
<!DOCTYPE html>
<html>
<head>
<title>
Example Domain
</title>
<meta charset="utf-8"/>
<meta content="text/html; charset=utf-8" http-equiv="Content-type"/>
<meta content="width=device-width, initial-scale=1" name="viewport"/>
<style type="text/css">
body {
background-color: #f0f0f2;
margin: 0;
padding: 0;
font-family: -apple-system, system-ui, BlinkMacSystemFont, "Segoe UI", "Open Sans", "Helvetica Neue", Helvetica, Arial, sans-serif;
}
div {
width: 600px;
margin: 5em auto;
padding: 2em;
background-color: #fdfdff;
border-radius: 0.5em;
box-shadow: 2px 3px 7px 2px rgba(0,0,0,0.02);
}
a:link, a:visited {
color: #38488f;
text-decoration: none;
}
@media (max-width: 700px) {
div {
margin: 0 auto;
width: auto;
}
}
</style>
</head>
<body>
<div>
<h1>
Example Domain
</h1>
<p>
This domain is for use in illustrative examples in documents. You may use this
domain in literature without prior coordination or asking for permission.
</p>
<p>
<a href="https://www.iana.org/domains/example">
More information...
</a>
</p>
</div>
</body>
</html>bs4의 .prettify() 메서드를 사용하면 html 파일 텍스트를 들여쓰기가 포함된 상태로 읽기 편하게 만들어준다.
2. .title / .head / .body : 각 태그 별 내용 가져오기
# title 가져오기
soup.title
# head 가져오기
soup.head
# body 가져오기
soup.bodytitle, head, body와 같이 html 문서 별 하나씩만 존재하는 태그의 경우 위와 같이 가져올 수 있다.
3. .find(): 특정 태그로 감싸진 요소 하나 찾기
# <h1> 태그로 감싸진 요소 하나 찾기
soup.find('h1')
>>>
<h1>Example Domain</h1>.find() 메서드를 사용하면 특정 태그로 감싸진 요소 (맨 위에 있는 것을 반환)를 찾을 수 있다.
4. .find_all(): 특정 태그로 감싸진 요소 모두 찾기
# <p> 태그로 감싸진 요소 모두 찾기
soup.find_all('p')
>>>
[<p>This domain is for use in illustrative examples in documents. You may use this
domain in literature without prior coordination or asking for permission.</p>,
<p><a href="https://www.iana.org/domains/example">More information...</a></p>].find_all 메서드를 사용하면 특정 태그로 감싸진 요소를 모두 찾아내 리스트 형태로 반환한다.
5. .name / .text: 해당 요소의 태그 이름 or 태그 내용 가져오기
# 해당 태그로 감싸진 요소 찾아 변수에 저장
h1 = soup.find("h1")
# 태그 이름 가져오기
h1.name # 'h1'
# 태그 내용 가져오기
h1.text # 'Example Domain'
원하는 요소 가져오기
본격적으로 원하는 요소를 가져오는 과정을 살펴보자. 우선 아래 링크의 웹페이지를 이용할 예정이다.
http://books.toscrape.com/catalogue/category/books/travel_2/index.html
Travel | Books to Scrape - Sandbox
£56.88 In stock
books.toscrape.com
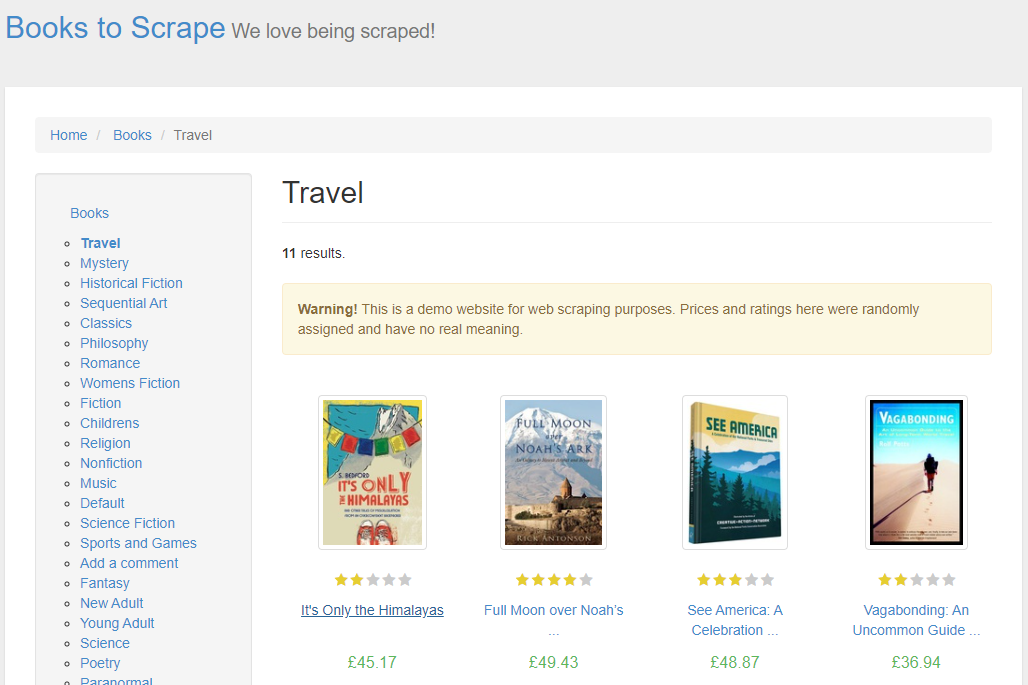
웹페이지에 접속하면 위와 같이 책 목록이 나열되어 있는 웹페이지가 노출된다. 여기서 책 제목들을 수집하는 과정을 살펴보고자 한다.
우선, 책 제목이 어떤 태그로 감싸져 있는지 알아야한다. Ctrl + Shift + C를 눌러 개발자 도구의 커서 기능을 이용해 책 제목 부분에 마우스를 가져가면, 아래와 같이 어떤 태그에 속해있는지 노출된다.
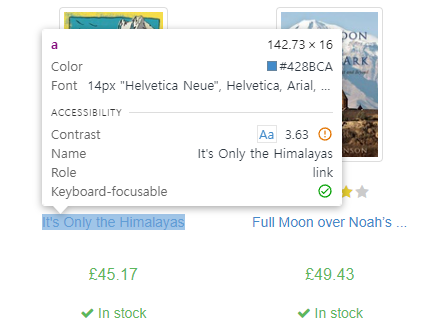
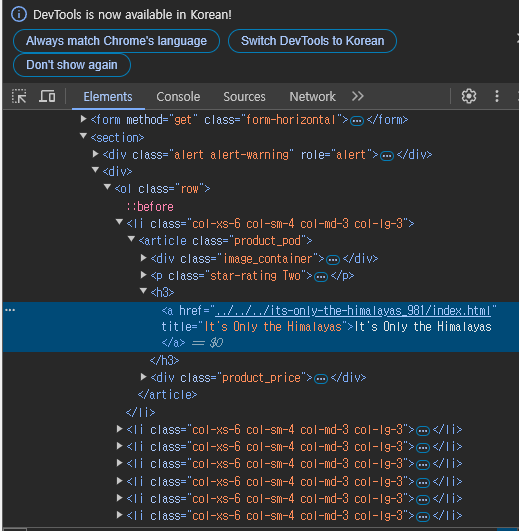
하지만 a 태그로 감싸져 있는 문구가 모두 책 제목이라 할 수는 없다. 책 제목 말고도 좌측 메뉴 버튼들도 모두 a 태그로 감싸져 있기 때문이다. 수집하고자 하는 항목의 공통점을 찾아 해당 부분만 수집할 수 있도록 해야한다.
책 제목의 경우 a 태그 상위 태그로 h3 태그가 감싸져 있는 걸 알 수 있다. 다행히도 h3태그 안에 a태그가 감싸져 있는 것은 책 제목이 유일하므로, h3 태그를 수집한 뒤 내용을 살펴보면 책 제목을 수집할 수 있을 것이다.
이제 코드를 통해 저 요소를 수집해보자.
import requests
from bs4 import BeautifulSoup
res = requests.get("http://books.toscrape.com/catalogue/category/books/travel_2/index.html")
soup = BeautifulSoup(res.text, 'html')requests를 통해 정보를 받은 뒤, soup을 통해 파싱해준다.
soup.find('h3')
>>>
<h3><a href="../../../its-only-the-himalayas_981/index.html" title="It's Only the Himalayas">It's Only the Himalayas</a></h3>h3 태그를 가지고 있는 요소 하나를 출력해 우리가 원하는 요소인지 확인한다.
# h3 태그 요소 모두 찾기 (리스트로 반환)
book_list = soup.find_all('h3')
for b in book_list:
print(b.text)
>>>
It's Only the Himalayas
Full Moon over Noahâs ...
See America: A Celebration ...
Vagabonding: An Uncommon Guide ...
Under the Tuscan Sun
A Summer In Europe
The Great Railway Bazaar
A Year in Provence ...
The Road to Little ...
Neither Here nor There: ...
1,000 Places to See ....find_all() 메서드를 통해 h3 태그에 감싸진 요소를 모두 찾은 뒤, 반복문을 통해 그 안에 담긴 내용을 모두 출력한다.
책 제목이 잘 나오나 싶었지만, 길이가 긴 책 제목의 경우 ...과 같은 점으로 표시되어 나타나는 것을 알 수 있다.
<h3><a href="../../../its-only-the-himalayas_981/index.html" title="It's Only the Himalayas">It's Only the Himalayas</a></h3>태그 내용을 다시 자세히 보면, a 태그 안에 title이라는 항목에 온전한 책 제목이 들어가 있는 것을 알 수 있다.
# a 태그 안의 'title' 항목을 출력
for b in book_list:
print(b.a['title'])
>>>
It's Only the Himalayas
Full Moon over Noahâs Ark: An Odyssey to Mount Ararat and Beyond
See America: A Celebration of Our National Parks & Treasured Sites
Vagabonding: An Uncommon Guide to the Art of Long-Term World Travel
Under the Tuscan Sun
A Summer In Europe
The Great Railway Bazaar
A Year in Provence (Provence #1)
The Road to Little Dribbling: Adventures of an American in Britain (Notes From a Small Island #2)
Neither Here nor There: Travels in Europe
1,000 Places to See Before You Die.a 를 이용해 a 태그에 접근한 다음, a['title']과 같이 딕셔너리를 호출하듯 출력해준다. title이 온전히 출력되는 것을 알 수 있다.
HTML의 Locator를 이용해 원하는 요소 찾기 (id, class)
HTML의 태그는 이름 뿐만 아니라 고유 속성도 가질 수 있다. 그 속성 중 id와 class는 Locator로, 특정 태그를 지칭하는 데 사용된다.
<p id="target">this element has id</p>
<p class="targets">this element has class</p>이 Locator를 이용하면, 태그이름을 통해서 찾는 것보다 더 쉽게 원하는 요소를 찾을 수 있을 것이다.
스포키 : STATIZ
정확한 이메일 주소를 입력해주세요. 취소 확인
statiz.sporki.com
프로야구 관련 선수/팀의 여러 지표를 보여주는 스탯티즈를 대상으로 실습을 진행해보겠다.
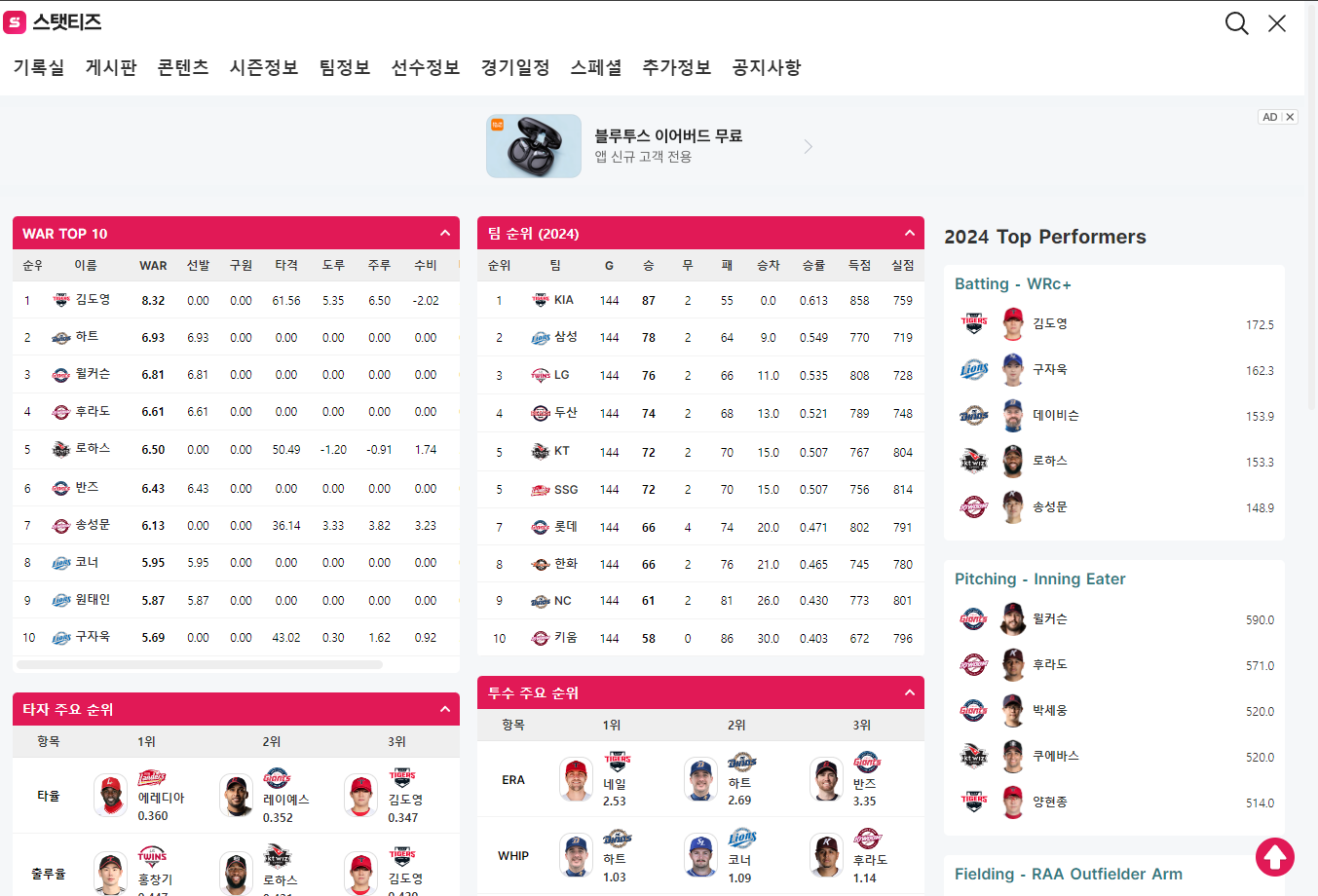
메인 페이지는 이렇게 노출된다. 이 중 WAR TOP 10에 해당하는 선수들의 이름을 스크래핑 해보자.
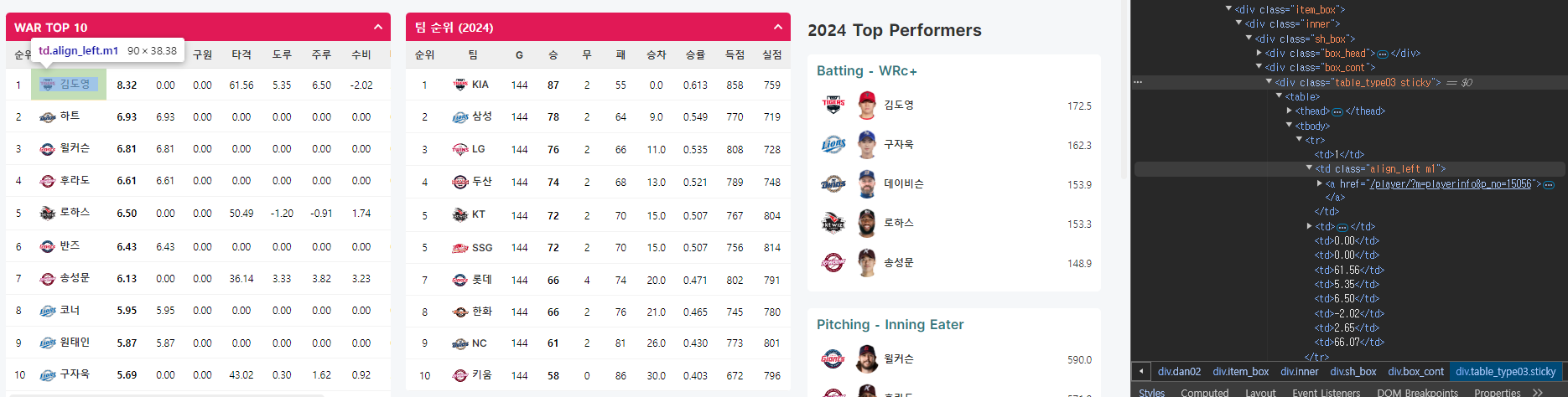
선수 이름을 감싸고 있는 태그를 살펴보자. class를 살펴보니, "table_type03 stickty"라는 클래스의 div 태그 속 "align_left m1" td 태그의 a태그를 살펴보면 선수 이름이 나온다는 것을 알 수 있다.
div class="table_type03 stickty" > table > tbody > tr > td class= "align_left m1" > a > 선수이름
언뜻봐서는 과정이 매우 길어보이지만, 클래스를 이용한다면 간단해진다.
# 필요 라이브러리 임포트
import requests
from bs4 import BeautifulSoup as bs# 응답받은 뒤 HTML 파싱
res = requests.get('https://statiz.sporki.com/')
soup = bs(res.text, 'html')
라이브러리를 통해 응답과 파싱을 한 다음, 클래스 이름을 통해 요소를 찾아본다.
# div 태그 중 "table_type03 sticky" 클래스를 가진 것을 하나 찾음
div = soup.find("div","table_type03 sticky")
# td 태그 중 "align_left m1" 클래스를 가진 것을 모두 찾음
td = div.find_all("td", "align_left m1")
td 변수 안에 찾은 요소들은 아래와 같다.
print(td)
>>>
[<td class="align_left m1"><a href="/player/?m=playerinfo&p_no=15056"><img src="/data/team/ci/2024/2002.svg" width="20"/> 김도영</a></td>,
<td class="align_left m1"><a href="/player/?m=playerinfo&p_no=16065"><img src="/data/team/ci/2024/11001.svg" width="20"/> 하트</a></td>,
<td class="align_left m1"><a href="/player/?m=playerinfo&p_no=12295"><img src="/data/team/ci/2024/3001.svg" width="20"/> 윌커슨</a></td>,
<td class="align_left m1"><a href="/player/?m=playerinfo&p_no=15531"><img src="/data/team/ci/2024/10001.svg" width="20"/> 후라도</a></td>,
<td class="align_left m1"><a href="/player/?m=playerinfo&p_no=12995"><img src="/data/team/ci/2024/12001.svg" width="20"/> 로하스</a></td>,
<td class="align_left m1"><a href="/player/?m=playerinfo&p_no=15011"><img src="/data/team/ci/2024/3001.svg" width="20"/> 반즈</a></td>,
<td class="align_left m1"><a href="/player/?m=playerinfo&p_no=11376"><img src="/data/team/ci/2024/10001.svg" width="20"/> 송성문</a></td>,
<td class="align_left m1"><a href="/player/?m=playerinfo&p_no=15860"><img src="/data/team/ci/2024/1001.svg" width="20"/> 코너</a></td>,
<td class="align_left m1"><a href="/player/?m=playerinfo&p_no=14113"><img src="/data/team/ci/2024/1001.svg" width="20"/> 원태인</a></td>,
<td class="align_left m1"><a href="/player/?m=playerinfo&p_no=10892"><img src="/data/team/ci/2024/1001.svg" width="20"/> 구자욱</a></td>]td 태그 안에 텍스트는 선수 이름밖에 없기 때문에, a태그까지 갈 필요없이 바로 텍스트를 출력하면 선수이름이 나올 것이다.
for t in td:
print(t.text)
>>>
김도영
하트
윌커슨
후라도
로하스
반즈
송성문
코너
원태인
구자욱
동적 웹페이지를 다루기 위한 라이브러리 - Selenium
정적 웹사이트와 동적 웹사이트
정적 웹사이트 - HTML 내용이 고정된 정적(static) 웹 사이트
- HTML 문서가 응답할 때 완전하게 응답됨
동적 웹사이트 - HTML 내용이 변하는 동적(dynamic) 웹 사이트 (ex. 유튜브, 인스타그램)
- 응답 후 HTML이 렌더링 될 때까지의 지연시간이 존재함 (바로 정보를 추출하기 어려움)
- jsp의 경우 비동기 처리를 통해 필요한 데이터를 채우기 때문에, 데이터 처리와 렌더링 시간이 서로 다름
- 키보드 입력, 마우스 클릭 등의 동작이 필요할 수 있음
Selenium으로 웹 브라우저를 조작하기
우선 pip 명령어를 통해 selenium 라이브러리를 설치해보자.
* 현재 Selenium은 Chromedriver 설치가 따로 필요없다. 라이브러리 설치 시 Chrome 버전에 맞춰 자동 설치된다.
pip install selenium
설치가 끝났다면 임의의 웹 사이트를 한번 열어보자. 나의 경우 KBO 홈페이지의 경기 일정 페이지를 열어봤다.
from selenium import webdriver
url = "https://www.koreabaseball.com/Schedule/Schedule.aspx"
options = Options()
driver = webdriver.Chrome(options=options)
driver.get(url)
특정 요소 추출해보기(By)
- .find_element(by, target): 요소 중 가장 위에 있는 하나를 찾음
- .find_elements(by, traget): 해당 요소를 모두 찾음
- by: 대상을 찾는 기준(ID, TAG_NAME, CLASS_NAME)
- target: 대상의 속성
# By를 사용하기 위해 import
from selenium.webdriver.common.by import BySelenium의 By모듈을 이용해서 웹 브라우저 상 원하는 요소를 가져올 수 있다.
KBO 경기일정 페이지에서 경기일정 테이블 자체를 가져온다고 생각해보자. 크롬의 개발자 도구를 이용해서 해당 위치를 살펴본 결과 class이름이 "tbl-type06"로 표시된다. 이를 활용해보자.
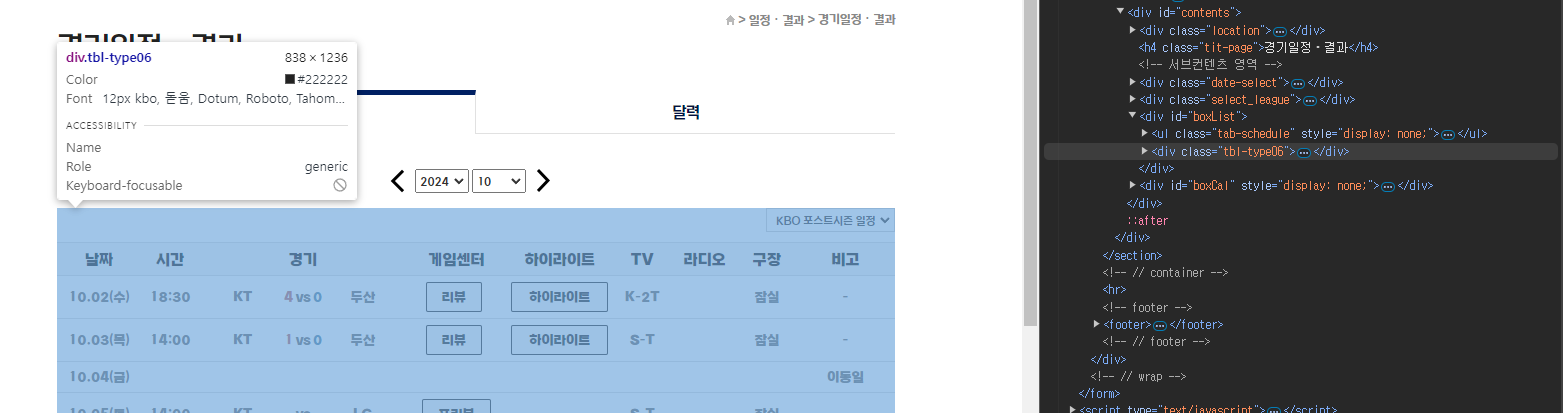
# 접속할 url
url = "https://www.koreabaseball.com/Schedule/Schedule.aspx"
# 옵션(
options = Options()
options.add_argument("--headless") # 브라우저를 열지 않도록 설정
options.add_argument('--no-sandbox') # Linux 같은 GUI 환경을 지원하지 않는 곳에서 사용
driver = webdriver.Chrome(options=options)
driver.get(url)
# 클래스 이름 "tbl-type06"을 찾고 해당 텍스트 출력
print(driver.find_element(By.CLASS_NAME, "tbl-type06").text)
>>>
날짜 시간 경기 게임센터 하이라이트 TV 라디오 구장 비고
10.02(수) 18:30 KT4vs0두산 리뷰 하이라이트 K-2T 잠실 -
10.03(목) 14:00 KT1vs0두산 리뷰 하이라이트 S-T 잠실 -
10.04(금) 이동일
10.05(토) 14:00 KTvsLG 프리뷰 S-T 잠실 -
10.06(일) 14:00 KTvsLG 프리뷰 M-T 잠실 -
10.07(월) 이동일
...위 코드 12~13번째 줄에서 해당 클래스 이름을 찾고 텍스트를 출력하는 것을 볼 수 있다.
Selenium을 활용 시 유용한 기능들
1. 명시적 기다림(Explicit Wait)과 암묵적 기다림(Implicit Wait)
- Implicit Wait: 웹 페이지가 다 로딩이 될 때까지 지정한 시간동안 기다림(ex. 5초동안 기다리기)
- Explicit Wait: 특정 요소에 대한 제약을 통한 기다림 (ex. 해당 태그를 가져올 수 있을 때까지 기다리기)
이 실습에서는 xpath를 사용해 볼 예정이다. 왜 Xpath를 사용할까?
- 스크래핑 방지 목적으로 class 이름을 랜덤하게 생성할 경우 Xpath 사용
- Xpath: XML, HTML 문서 등의 요소의 위치를 경로로 표현하는 것
.explicit_wait() : 명시적 기다림
- Explicit Wait은 WebDriverWait()과 두 메서드를 활용해서 적용할 수 있음
- .until() 또는 until_not() 메서드를 활용 (인자의 조건이 만족되거나 / 만족되지 않을 때까지)
from selenium.webdriver.support.ui import WebDriverWait
from selenium.webdriver.support import expected_conditions as EC
# id가 target인 요소가 존재할 때까지 기다린 후 명령 진행
element = WebDriverWait(driver, 10).until(EC.presence_of_element_located((By.ID, "target")))
.implicitly _wait() : 명시적 기다림
- implicitly_wait()은 암묵적 기다림으로, 웹 페이지가 모두 로딩될 때 까지 기다린다.
- 인자에는 한계 시간이 들어간다.
- ex) .implicitly _wait(10): 웹 페이지가 모두 로딩될 때까지 기다리지만 10초를 넘지는 않음
from selenium.webdriver.support.ui import WebDriverWait
# 10초를 한계로 로딩이 완벽히 될 때까지 기다림
driver.implicitly_wait(10)
driver.find_element(By.XPATH, '//*[@id="tblScheduleList"]/tbody/tr[1]/td[1]')
2. 마우스 이벤트 처리
.click() : 마우스 '클릭' 처리
# 클릭할 대상 요소 찾기
posting = driver.find_element(By.XPATH, '//*[@id="rso"]/div[1]/div/div/div[1]/div/div/div[1]/div/a/h3')
posting.click()
3. 키보드 이벤트 처리
.send_keys(): 입력하고자 하는 내용 전달
from selenium.webdriver.common.keys import Keys
# 입력할 요소 선택
search_box = driver.find_element(By.XPATH, '//*[@id="tsf"]/div[2]/div[1]/div[1]/div/div[2]/input')
search_box.send_keys('네이버')
특수 키 입력할 경우
from selenium.webdriver.common.keys import Keys
# 엔터 입력
search_box.send_keys(Keys.RETURN)Keys 클래스를 불러와 특수 키를 입력할 수도 있다. 입력할 수 있는 특수 키는 아래와 같다.
class Keys(object):
"""
Set of special keys codes.
"""
NULL = '\ue000'
CANCEL = '\ue001' # ^break
HELP = '\ue002'
BACKSPACE = '\ue003'
BACK_SPACE = BACKSPACE
TAB = '\ue004'
CLEAR = '\ue005'
RETURN = '\ue006'
ENTER = '\ue007'
SHIFT = '\ue008'
LEFT_SHIFT = SHIFT
CONTROL = '\ue009'
LEFT_CONTROL = CONTROL
ALT = '\ue00a'
LEFT_ALT = ALT
PAUSE = '\ue00b'
ESCAPE = '\ue00c'
SPACE = '\ue00d'
PAGE_UP = '\ue00e'
PAGE_DOWN = '\ue00f'
END = '\ue010'
HOME = '\ue011'
LEFT = '\ue012'
ARROW_LEFT = LEFT
UP = '\ue013'
ARROW_UP = UP
RIGHT = '\ue014'
ARROW_RIGHT = RIGHT
DOWN = '\ue015'
ARROW_DOWN = DOWN
INSERT = '\ue016'
DELETE = '\ue017'
SEMICOLON = '\ue018'
EQUALS = '\ue019'
NUMPAD0 = '\ue01a' # number pad keys
NUMPAD1 = '\ue01b'
NUMPAD2 = '\ue01c'
NUMPAD3 = '\ue01d'
NUMPAD4 = '\ue01e'
NUMPAD5 = '\ue01f'
NUMPAD6 = '\ue020'
NUMPAD7 = '\ue021'
NUMPAD8 = '\ue022'
NUMPAD9 = '\ue023'
MULTIPLY = '\ue024'
ADD = '\ue025'
SEPARATOR = '\ue026'
SUBTRACT = '\ue027'
DECIMAL = '\ue028'
DIVIDE = '\ue029'
F1 = '\ue031' # function keys
F2 = '\ue032'
F3 = '\ue033'
F4 = '\ue034'
F5 = '\ue035'
F6 = '\ue036'
F7 = '\ue037'
F8 = '\ue038'
F9 = '\ue039'
F10 = '\ue03a'
F11 = '\ue03b'
F12 = '\ue03c'
META = '\ue03d'
COMMAND = '\ue03d'
.send_keys()를 통해 파일도 업로드 할 수 있다.
upload = driver.find_element(By.TAG_NAME, 'input')
upload.send_keys(file_path)
.clear(): 텍스트 입력 지우기
search_box.clear()
4. ActionChains
ActionChains는 마우스,키보드 등 동작이 연속적으로 일어나야할 때 사용하기 유용한 기능이다. 수행할 동작을 하나의 변수에 저장한 뒤 차례로 동작하게 할 수 있다. ActionChains를 실행할 때에는 .perform() 메서드를 사용한다.
from selenium.webdriver import ActionChains
menu = driver.find_element(By.CSS_SELECTOR, '.nav')
hidden_submenu = driver.find_element(By.CSS_SELECTOR, '.nav #submenu1')
# menu로 이동한 뒤 hidden_submenu를 클릭하는 연속 동작
ActionChains(driver).move_to_element(menu).click(hidden_submenu).perform()
ActionChains의 동작 메서드들
| click(on_element=None) | 인자로 주어진 요소 클릭 |
| click_and_hold(on_element=None) | 인자로 주어진 요소를 클릭하고 누르고 있기 |
| release(on_element=None) | 마우스를 주어진 요소에서 떼기 |
| context_click(on_element=None) | 인자로 주어진 요소 오른쪽 클릭 |
| double_click(on_element=None) | 인자로 주어진 요소 더블클릭 |
| drag_and_drop(source, target) | 요소를 클릭한 뒤 계속 누른 채로 target까지 이동한 뒤 클릭 해제 |
| drag_and_drop_by_offset(source, xoffset, yoffset) | offset만큼 이동하여 클릭 해제 (위 함수와 비슷) |
| key_down(value, element=None) | value로 주어진 키를 계속 누르기 |
| key_up(value, element=None) | value로 주어진 키를 떼기 |
| move_to_element(to_element) | 커서를 해당 요소의 중간 위치로 이동 |
| move_to_element_with_offset(to_element, xoffset, yoffset) | 커서를 해당 요소에서 offset만큼 이동한 위치로 이동 |
| pause(seconds) | 주어진 시간(초 단위)만큼 입력 중지 |
| perform() | 이미 쌓여 있는(stored) 모든 행동 수행(chaining). |
| reset_actions() | 이미 쌓여 있는(stored) 모든 행동을 제거 |
| send_keys(*keys_to_send) | 키보드 입력을 현재 focused된 요소에 보내기 |
| send_keys_to_element(element, *keys_to_send) | 키보드 입력을 주어진 요소에 보내기 |
4. 브라우저 창 관련 조작
.forward(), back(): 앞으로가기, 뒤로가기
driver.forward()
driver.back()
화면 이동
# 웹페이지의 최 하단으로 내려가기
driver.execute_script('window.scrollTo(0, document.body.scrollHeight);')
# 특정 요소가 나올때까지 ActionChains를 사용해도 됨.
from selenium.webdriver import ActionChains
some_tag = driver.find_element(By.ID, 'gorio')
ActionChains(driver).move_to_element(some_tag).perform()
브라우저 최소화/최대화
driver.minimize_window()
driver.maximize_window()
스크린샷 저장
driver.save_screenshot('screenshot.png')
5. driver 옵션 (Option / ChromeOption)
options = webdriver.ChromeOptions()
# 창 띄우지 않기
options.add_argument('headless')
# 창 크기 지정
options.add_argument('window-size=1920x1080')
# gpu 사용하지 않기
options.add_argument('disable-gpu')
# 최대화된 상태로 시작
options.add_argument('start-maximized')
# 브라우저 상단 정보 바를 비활성화
options.add_argument('disable-infobars')
# 모든 Chrome 확장 프로그램을 비활성화 (일관성을 위함)
options.add_argument('--disable-extensions')
# 브라우저가 자동화 도구에 의해 제어되고 있다는 것을 나타내는 플래그 제거
options.add_experimental_option('excludeSwitches', ['enable-automation'])
# Chrome의 자동화 확장 기능을 비활성화 (봇 탐지 회피용)
options.add_experimental_option('useAutomationExtension', False)
# Blink 렌더링 엔진의 AutomationControlled 기능을 비활성화 (브라우저 자동화 감지 회피용)
options.add_argument('--disable-blink-features=AutomationControlled')
# 이미 실행 중인 Chrome 인스턴스에 연결할 수 있게 해줌(로컬 크롬에도 접근 가능)
options.add_experimental_option('debuggerAddress', '127.0.0.1:XXXX')
'Minding's Programming > Crawling' 카테고리의 다른 글
| [Playwright/Python] 비동기 처리가 가능한 웹 스크래핑 라이브러리, Playwright (0) | 2024.10.23 |
|---|---|
| [HTTP/Python] HTTP 통신, 웹 스크래핑/크롤링 기본 개념 정리 (1) | 2024.10.02 |
| [Python/Selenium] (업데이트)Selenium으로 KBO 경기 일정 크롤링하기 (0) | 2024.07.09 |
| [Python/Selenium] Selenium으로 KBO 경기 일정 크롤링하기 (0) | 2024.07.01 |
| [Python/Bleach] Bleach 라이브러리 이용해 HTML 태그 삭제하기 (0) | 2024.06.26 |