728x90
반응형
https://dataq.goorm.io/exam/116674/%EC%B2%B4%ED%97%98%ED%95%98%EA%B8%B0/quiz/1
구름EDU - 모두를 위한 맞춤형 IT교육
구름EDU는 모두를 위한 맞춤형 IT교육 플랫폼입니다. 개인/학교/기업 및 기관 별 최적화된 IT교육 솔루션을 경험해보세요. 기초부터 실무 프로그래밍 교육, 전국 초중고/대학교 온라인 강의, 기업/
edu.goorm.io
1번문제

import pandas as pd
df = pd.read_csv('data/mtcars.csv', index_col=0)
# 사용자 코딩
from sklearn.preprocessing import minmax_scale
df['qsec'] = minmax_scale(df['qsec'])
record = len(df[df['qsec'] > 0.5])
print(record)
>>> 9
2번문제
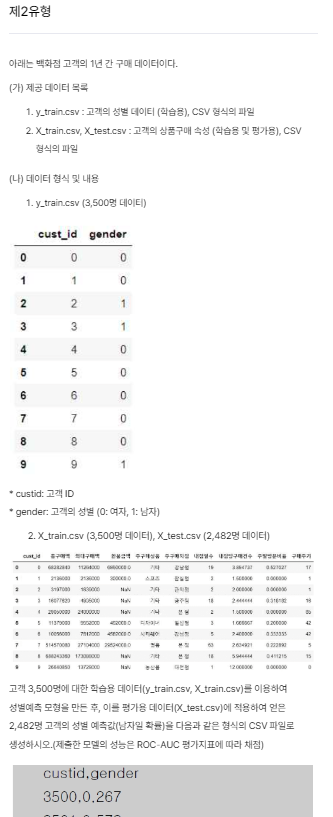
# 출력을 원하실 경우 print() 함수 활용
# 예시) print(df.head())
# getcwd(), chdir() 등 작업 폴더 설정 불필요
# 파일 경로 상 내부 드라이브 경로(C: 등) 접근 불가
# 데이터 파일 읽기 예제
import pandas as pd
X_test = pd.read_csv("data/X_test.csv")
X_train = pd.read_csv("data/X_train.csv")
y_train = pd.read_csv("data/y_train.csv")
# 사용자 코딩
# EDA
print(X_train.info())
# 데이터 전처리 (결측값 제거)
X_train = X_train.fillna(0)
X_test = X_test.fillna(0)
# 학습에 필요없는 칼럼 제거
X_train = X_train.drop(['cust_id'], axis=1)
cust_id = X_test.pop('cust_id')
# feature Engineering (Category형 칼럼 인코딩)
from sklearn.preprocessing import LabelEncoder
cols = ['주구매상품', '주구매지점']
for col in cols:
le = LabelEncoder()
X_train[col] = le.fit_transform(X_train[col])
X_test[col] = le.fit_transform(X_test[col])
# 모델링 & 하이퍼파라미터 튜닝 & 앙상블
from sklean.ensemble import RandomForestClassifier
model = RandomForestClassifier(n_estimator=100, max_depth=5, random_state=2022)
model.fit(X_train, y['gender'])
predictions = model.predict_proba(X_test)
# csv
output = pd.DataFrame({'cust_id' : cust_id, 'gender' : predictions[:,1]})
output.to_csv('0000.csv', index=False)
3번문제

# 출력을 원할 경우 print() 함수 활용
# 예시) print(df.head())
# getcwd(), chdir() 등 작업 폴더 설정 불필요
# 파일 경로 상 내부 드라이브 경로(C: 등) 접근 불가
import pandas as pd
df = pd.read_csv('data/blood_pressure.csv', index_col=0)
# 1번문제 (치료 후 혈압 - 치료 전 혈압의 평균)
df['diff'] = df['bp_after'] - df['bp_before']
bp_mean = round(df['diff'].mean(),2)
print(bp_mean)
>>> -5.09
# 2번문제 (검정통계량) - scipy의 ttest 라이브러리 활용
from scipy import stats
result = stats.ttest_rel(df['bp_before'], df['bp_after'], alternative = 'greater')
# ttest_rel의 alternative 파라미터 조절
# 대립가설의 독립변수가 종속변수 보다 커야할 경우 : greater
# 대립가설의 독립변수가 종속변수 보다 작아야할 경우 : less
# 독립변수와 종속변수가 다르기만 하면 될 경우 : two_sided(기본값)
print(result)
>>> Ttest_relResult(statistic=3.3371870510833657, pvalue=0.0005648957322420411)
print(round(result.statistic,4))
>>> 3.3372
# 3번문제 = 위의 result에서 해결
print(round(result.pvalue, 4))
>>> 0.0006
# 4번문제
# pvalue값이 0.05보다 작기때문에 대립가설 채택
print('채택')
# 해당 화면에서는 제출하지 않으며, 문제 풀이 후 답안제출에서 결괏값 제출
728x90
'Minding's Programming > Kaggle and Dacon' 카테고리의 다른 글
| [Dacon] 랜드마크 분류 문제 소개 (0) | 2021.05.09 |
|---|---|
| [Kaggle] House Prices Prediction : 보스턴 주택가격 예측 - 2. Modeling & Prediction (0) | 2021.04.14 |
| [Kaggle] House Prices Prediction : 보스턴 주택가격 예측 - 1. EDA & Feature Engineering (4) | 2021.04.14 |


